ClickHouse 24.10 版本发布说明
 admin
发表于 2024-11-25 17:27
admin
发表于 2024-11-25 17:27|
又到了新版本发布的时间! 发布概要 本次ClickHouse 24.10 版本包含了25个新功能🎁、15项性能优化🛷、60个bug修复🐛 在本次发布中,clickhouse-local 更加实用,新增了复制和计算器模式。可刷新物化视图已达到生产就绪标准,远程文件支持缓存,表克隆操作也得到了简化。
正如往常,我们热烈欢迎所有 24.9 版本中的新贡献者!ClickHouse 的流行离不开社区的积极贡献,见证这个社区的壮大总是令人感到鼓舞。 以下是新加入的贡献者名单: Alsu Giliazova, Baitur, Baitur Ulukbekov, Damian Kula, DamianMaslanka5, Daniil Gentili, David Tsukernik, Dergousov Maxim, Diana Carroll, Faizan Patel, Hung Duong, Jiří Kozlovský, Kaushik Iska, Konstantin Vedernikov, Lionel Palacin, Mariia Khristenko, Miki Matsumoto, Oleg Galizin, Patrick Druley, SayeedKhan21, Sharath K S, Shichao, Shichao Jin, Vladimir Cherkasov, Vladimir Valerianov, Z.H., aleksey, alsu, johnnyfish, kurikuQwQ, kylhuk, lwz9103, scanhex12, sharathks118, singhksandeep25, sum12, tuanpach 本次版本发布的线上 Webinar 视频。 视频相关 PPT 下载【https://presentations.clickhouse.com/release_24.10/】
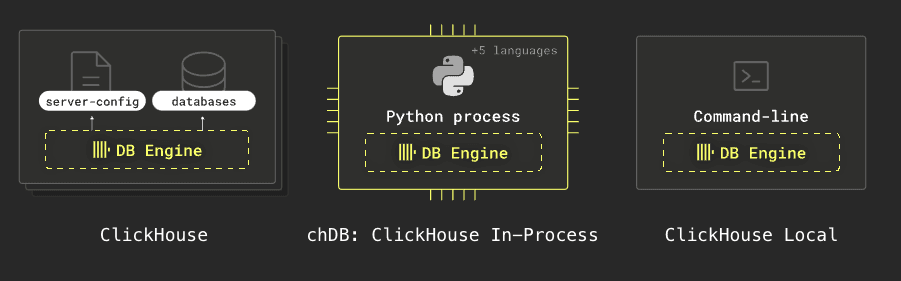
贡献者:Denis Hananein ClickHouse 提供多种形式,其中之一是 clickhouse-local。它无需安装数据库服务器即可使用 SQL 快速处理本地和远程文件。以下是 ClickHouse 各种形式的图示:
clickhouse-local 现在新增了一个标志 --copy,可以作为 SELECT * FROM table 的快捷方式。这使得在不同数据格式之间进行转换变得异常简单。 我们将从 datablist/sample-csv-files GitHub 仓库【https://github.com/datablist/sample-csv-files?tab=readme-ov-file】下载一个包含 100 万人数据的 CSV 文件,然后可以运行以下查询来生成该文件的 Parquet 版本: 我们可以通过以下查询来查看新文件的内容:
如果我们想将数据从 CSV 转换为 JSON lines 格式,可以执行以下操作: 接下来,我们看看新文件的内容:
贡献者:Alexey Milovidov clickhouse-local 现在还提供了“计算器模式”。通过 --implicit-select 标志,您可以直接运行表达式,而无需添加 SELECT 前缀。 例如,以下表达式计算当前时间前 23 分钟的时间:
贡献者:Tuan Pach 想象一下,您可以几乎瞬间创建一个大型表的一对一副本,并且不需要额外的存储空间。这在您希望对数据进行无风险实验时非常有帮助。 现在,通过使用 CLONE AS 子句,可以轻松实现这一点。使用该子句的效果就相当于创建一个空表并附加所有源表的分区。 当我们运行克隆操作时,ClickHouse 不会为新表复制数据,而是为新表创建了指向现有表部分的硬链接。 ClickHouse 的数据部分是不可变的,这意味着如果我们在任意一个表中添加新数据或修改数据,另一个表将不受影响。 例如,假设我们有一个名为 people 的表,它基于之前提到的 CSV 文件:
我们可以通过运行以下查询,将该表克隆到一个名为 people2 的新表: 现在,这两个表包含相同的数据。
但我们仍然可以分别向它们添加数据。例如,我们可以将 CSV 文件中的所有行添加到 people2 表中:
现在,让我们分别统计每个表中的记录数:
贡献者:Maria Khristenko, Julia Kartseva 在 ClickHouse 客户端或 clickhouse-local 中运行查询时,只需按下空格键,即可更细致地查看查询进展情况。 例如,假设我们运行一个查询:
如果在查询执行时按下空格键,我们将看到如下内容: 当查询结束时,还会显示以下统计数据:
贡献者:Kseniia Sumarokova 如果您曾运行过类似以下的查询:
您可能会发现,查询后续执行时速度略有提升,但提升不明显。 从 24.10 版本起,这种情况将有所改变!ClickHouse 现在支持直接访问的文件和在 S3、Azure 上的数据湖表的缓存。 缓存条目通过路径 + ETag 进行标识,ClickHouse 会缓存查询中引用的列的数据。要启用该功能,您需要在 ClickHouse 服务器配置文件中添加以下配置(当前不适用于 ClickHouse Local):
您可以通过运行 SHOW FILESYSTEM CACHES 来检查 ClickHouse 是否已启用文件系统缓存。随后,在执行查询时启用缓存并指定缓存名称即可:
除了查询时间外,您还可以在查询运行时按下空格键,实时查看 S3* 指标。以下是上述查询在未启用缓存和启用缓存时的指标对比:
启用缓存后:
显著差别在于 S3GetObject 请求的次数:未启用缓存时有 186 次,而启用缓存后降为 0 次。不过需要注意,缓存版本依然会发出 S3ListObjects 请求,以检测对象的 ETag 是否发生变化。 缓存采用 LRU(最近最少使用)淘汰策略。
贡献者:Michael Kolupaev 我们曾在 23.12 和 24.9 版本的发布博客中介绍过可刷新物化视图,当时它还是一项实验功能。 如今在 24.10 版本中,该功能不仅支持 Replicated 数据库引擎,而且已经可以正式应用于生产环境!
贡献者:Kirill Nikiforov ClickHouse 内置了超过 50 种外部系统的集成,包括 MongoDB。 通过 MongoDB 表函数或表引擎,ClickHouse 可以直接查询 MongoDB。表引擎适用于创建持久的代理表以查询远程 MongoDB 集合,而表函数则允许执行临时查询。 此前,这两种集成都存在一些显著的限制。例如,并非所有 MongoDB 数据类型都能被支持,同时 WHERE 和 ORDER BY 条件在查询时无法直接下推,而是先从 MongoDB 集合中读取所有未筛选、未排序的数据后,再在 ClickHouse 端处理。 ClickHouse 24.10 对 MongoDB 集成进行了全面优化和改进,新增了以下功能:
为了展示这些改进,我们在 AWS EC2 上安装了 MongoDB 8.0 社区版并导入了一些数据。在 MongoDB Shell (mongosh) 中运行以下命令查看导入的 JSON 文档之一: |















版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。