官宣了:ClickHouse 与 OpenTelemetry 的集成
 admin
发表于 2024-11-25 17:26
admin
发表于 2024-11-25 17:26
专栏
技术分享






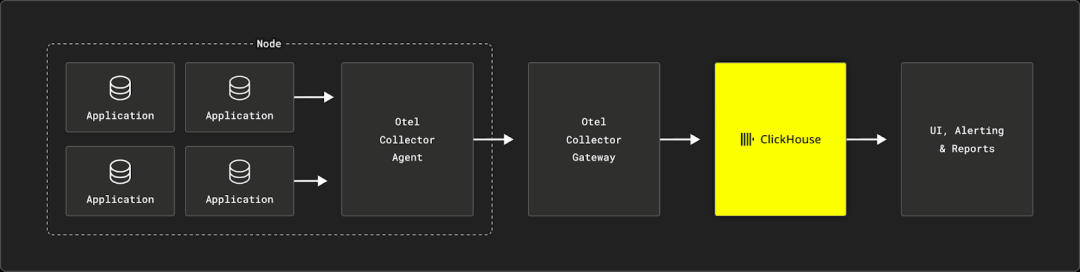

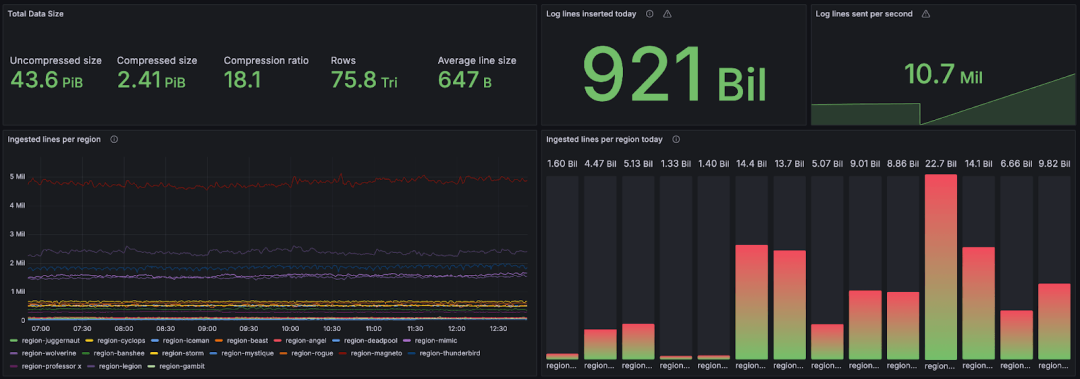



















版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。
评论