Trip.com 如何从 Elasticsearch 迁移到 ClickHouse 并构建了 50PB 的日志解决方案 ...
 admin
发表于 2024-10-15 15:09
admin
发表于 2024-10-15 15:09|
在 Trip.com,我们为用户提供广泛的数字产品,包括酒店和机票预订、景点、旅游套餐、商务旅行管理和与旅行相关的内容。正如你所猜的那样,我们需要一个可扩展、可靠且快速的日志平台,这对于我们的运营至关重要。 在我们开始之前,为了激起你的好奇心,让我展示一些我们在 ClickHouse 上构建的平台的关键数据:
这篇博客文章将讲述我们日志平台的故事,包括为什么我们最初构建它、我们使用的技术,以及我们在 ClickHouse 上利用 SharedMergeTree 等功能对其未来的规划。 以下是我们在旅程中将讨论的不同主题:
为了简化,让我们把这些内容放在一个时间线上:
每个伟大的故事都始于一个巨大的挑战。在我们的案例中,这个项目起源于 2012 年之前,因为 Trip.com 没有统一或集中的日志平台。每个团队和业务单元(BU)各自收集和管理自己的日志,这带来了许多不同的问题:
基于这些问题,我们意识到需要构建一个集中和统一的日志平台。 2012 年,我们推出了第一个平台。它建立在 Elasticsearch 之上,开始定义 ETL、存储、日志访问和查询的标准。 尽管我们不再使用 Elasticsearch 作为我们的日志平台,但值得探讨我们当初是如何实现这个解决方案的。它驱动了我们后来的许多工作,这是我们在后续迁移到 ClickHouse 时必须考虑的。
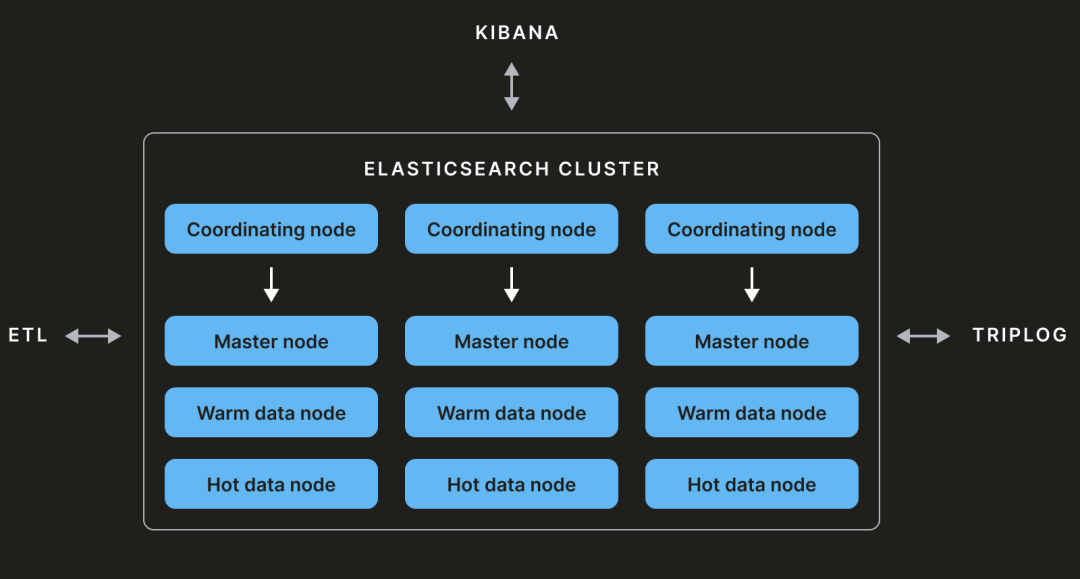
我们的 Elasticsearch 集群主要由主控节点、协调节点和数据节点组成。 主控节点 每个 Elasticsearch 集群至少由三个主控节点组成。其中一个将被选为主节点,负责维护集群状态。集群状态是包含有关各种索引、分片、副本等信息的元数据。任何修改集群状态的操作都会由主控节点执行。 数据节点 数据节点存储数据并用于执行增删改查(CRUD)操作。它们可以分为多个层次:热层、暖层等。 协调节点 这种类型的节点没有其他功能(如主控、数据、摄取、转换等),并通过考虑集群状态作为智能负载均衡器。如果协调节点接收到带有 CRUD 操作的查询,它会被发送到数据节点。相反,如果接收到添加或删除索引的查询,它会被发送到主控节点。
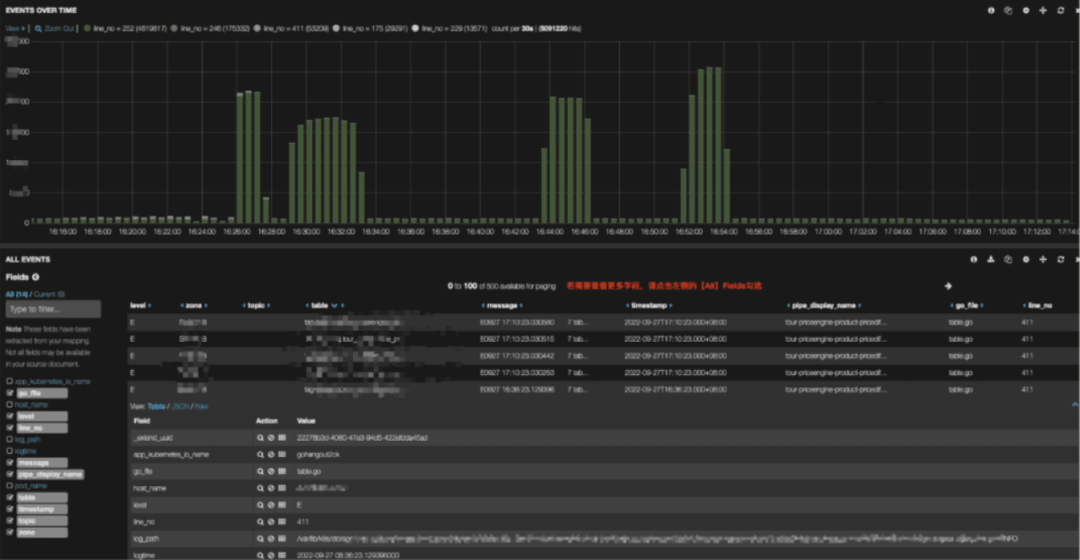
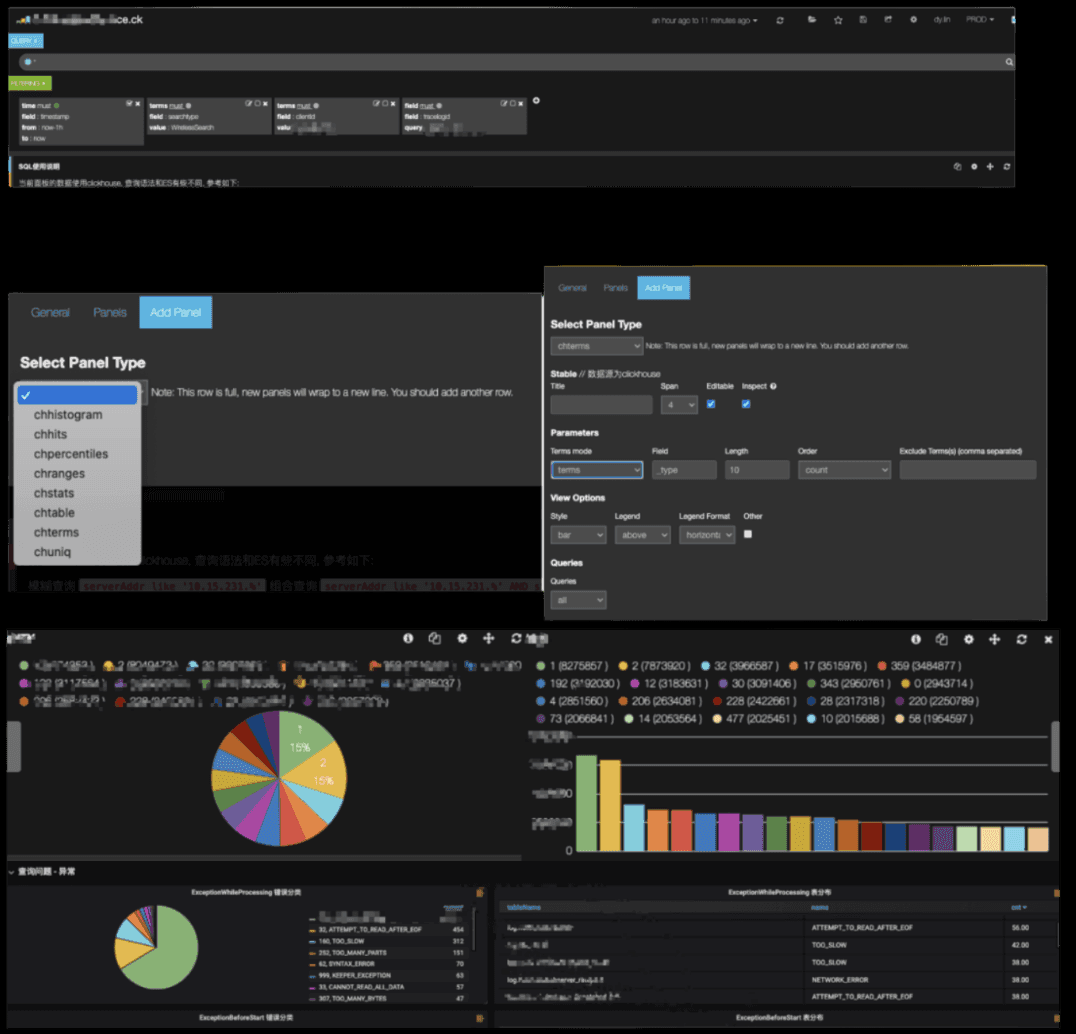
基于 Elasticsearch 我们使用 Kibana 作为可视化层。你可以在下方看到一个可视化示例:
我们的用户有两种方式将日志发送到平台:通过 Kafka 和通过代理。 通过 Kafka 第一种方法是使用公司的框架 TripLog 将数据导入 Kafka 消息代理(使用 Hermes)。
这为用户提供了一个轻松将日志发送到平台的框架。 通过代理工具 另一种方法是使用代理工具,如 Filebeat、Logstash、Logagent 或定制客户端,直接写入 Kafka。你可以在下面看到一个 Filebeat 配置示例:
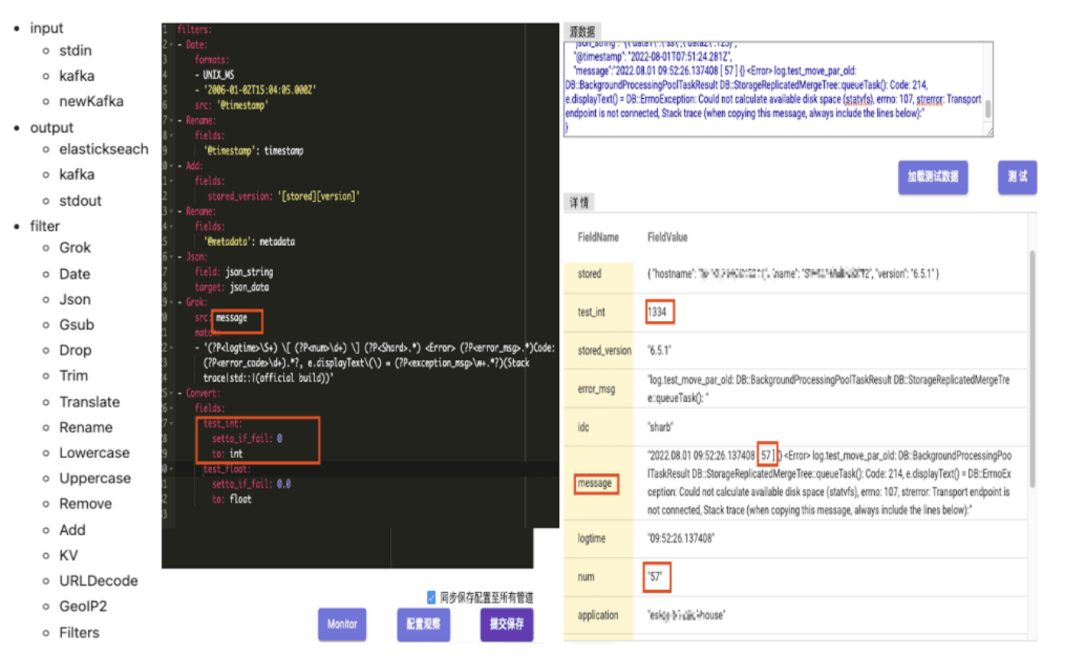
无论用户选择哪种方法,数据最终都会进入 Kafka,然后可以通过 gohangout 管道传输到 Elasticsearch。 Gohangout 是由 trip.com 开发和维护的开源应用程序,作为 Logstash 的替代方案。它旨在从 Kafka 获取数据,执行 ETL 操作,最终将数据输出到各种存储介质中,如 ClickHouse 和 Elasticsearch。Filter 模块中的数据处理包括常见的数据清洗功能,如 JSON 处理、Grok 模式匹配和时间转换(如下所示)。在下面的示例中,GoHangout 使用正则表达式匹配从 Message 字段提取 num 数据,并将其存储为单独的字段。
许多人使用 Elasticsearch 进行可观测性,在处理较小数据量时表现出色。它提供易于使用的软件、无模式体验、广泛的功能和流行的 Kibana 界面。然而,当我们这种大规模部署时,它存在一些众所周知的挑战。 当我们在 Elasticsearch 中存储 4PB 数据时,我们开始面临集群稳定性的多个问题:
关于集群性能:
最后,关于成本:
所以,在意识到以上所有问题后,我们寻找替代方案,于是 ClickHouse 出现了!
Elasticsearch 和 ClickHouse 之间存在一些基本差异;让我们来看看它们。 查询 DSL vs SQL Elasticsearch 依赖于一种特定的查询语言,称为查询 DSL(领域专用语言)。尽管现在有更多的选项,但这仍然是主要语法。另一方面,ClickHouse 依赖于 SQL,这是一种非常主流且非常用户友好的语言,并且与许多不同的集成和 BI 工具兼容。 内部机制 Elasticsearch 和 ClickHouse 在内部行为上有一些相似之处,Elasticsearch 生成段,而 ClickHouse 写入部分。虽然两者都会随着时间的推移异步合并,创建更大的部分和段,但 ClickHouse 通过列式模型区分自己,其中数据通过 ORDER BY 键排序。这允许构建稀疏索引,从而实现快速过滤和高效的存储使用,因为压缩率很高。你可以在这篇出色的指南中了解更多关于此索引机制的信息。 索引 vs 表 Elasticsearch 中的数据存储在索引中,并分解为分片。这些需要保持在相对较小的大小范围内(在我们使用时,推荐的是大约 50GB 的分片)。相比之下,ClickHouse 的数据存储在显著更大的表中(在 TB 范围内,如果不受磁盘大小限制的话,还可以更大)。除此之外,ClickHouse 允许你创建分区键,这会将数据物理上分隔到不同的文件夹中。如果需要,可以高效地操作这些分区。 总体而言,我们对 ClickHouse 的功能和特性印象深刻:它的列式存储、向量化查询执行、高压缩率和高插入吞吐量。这些满足了我们对日志解决方案在性能、稳定性和成本效益方面的需求。因此,我们决定使用 ClickHouse 来替换我们的存储和查询层。 下一个挑战是如何无缝地从一种存储迁移到另一种存储而不中断服务。
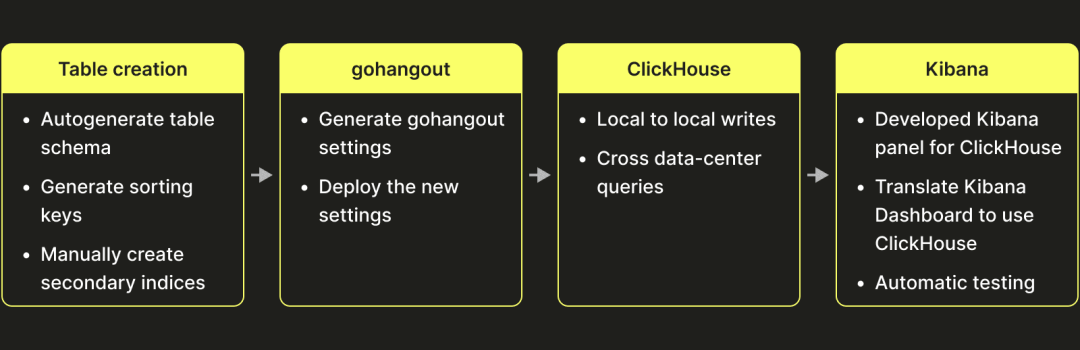
在决定迁移到 ClickHouse 之后,我们确定了需要完成的几个任务:
表设计 这是我们当时确定的初始表设计(请记住,那是几年前的事了,当时 ClickHouse 还没有现在的所有数据类型,例如 maps):
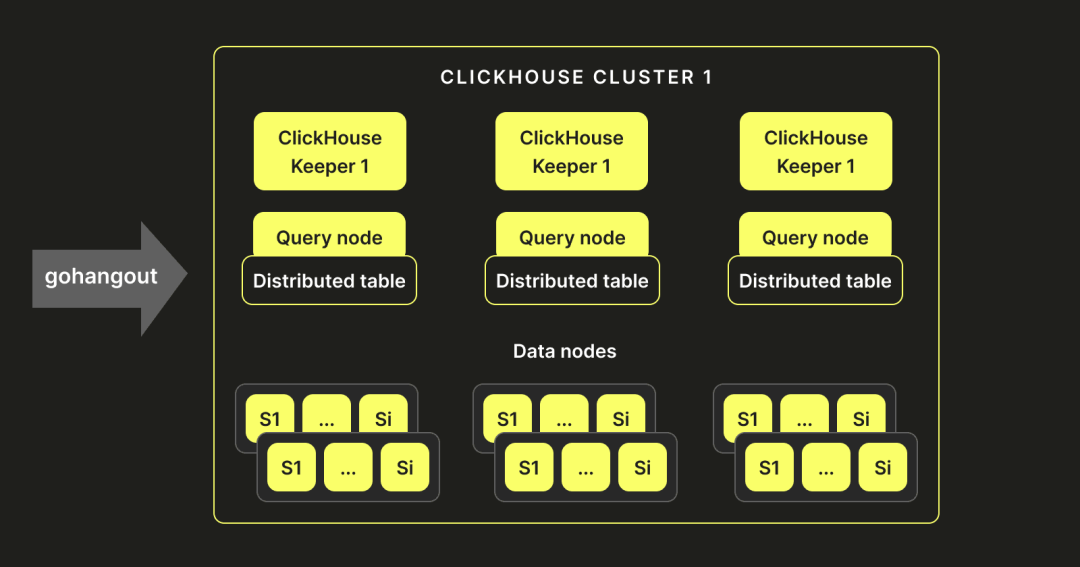
集群设置 鉴于我们在 Elasticsearch 上的历史设置和经验,我们决定复制一个相似的架构。我们的 ClickHouse-Keeper 实例充当主节点(类似于 Elasticsearch)。部署了多查询节点,这些节点不存储数据,而是持有指向 ClickHouse 服务器的分布式表。这些服务器托管数据节点,存储和写入数据。以下显示了我们最终的架构:
数据可视化 在迁移到 ClickHouse 后,我们希望为用户提供无缝体验。为此,我们需要确保所有的可视化和仪表板都能使用 ClickHouse。这带来了一个挑战,因为 Kibana 是一个最初在 Elasticsearch 上开发的工具,不支持其他存储引擎。因此,我们必须对其进行自定义,以确保它能够与 ClickHouse 接口。这需要我们在 Kibana 中创建新的数据面板,可以与 ClickHouse 一起使用:chhistogram、chhits、chpercentiles、chranges、chstats、chtable、chterms 和 chuniq。 然后,我们创建了脚本,将 95% 的现有 Kibana 仪表板迁移到使用 ClickHouse。最后,我们增强了 Kibana,使用户可以编写 SQL 查询。
我们的日志管道是自助服务,允许用户发送日志。这些用户需要能够创建索引并定义所有权、权限和 TTL 策略。因此,我们创建了一个名为 Triplog 的平台,为用户提供管理表、用户和角色的接口,监控其数据流,并创建警报。
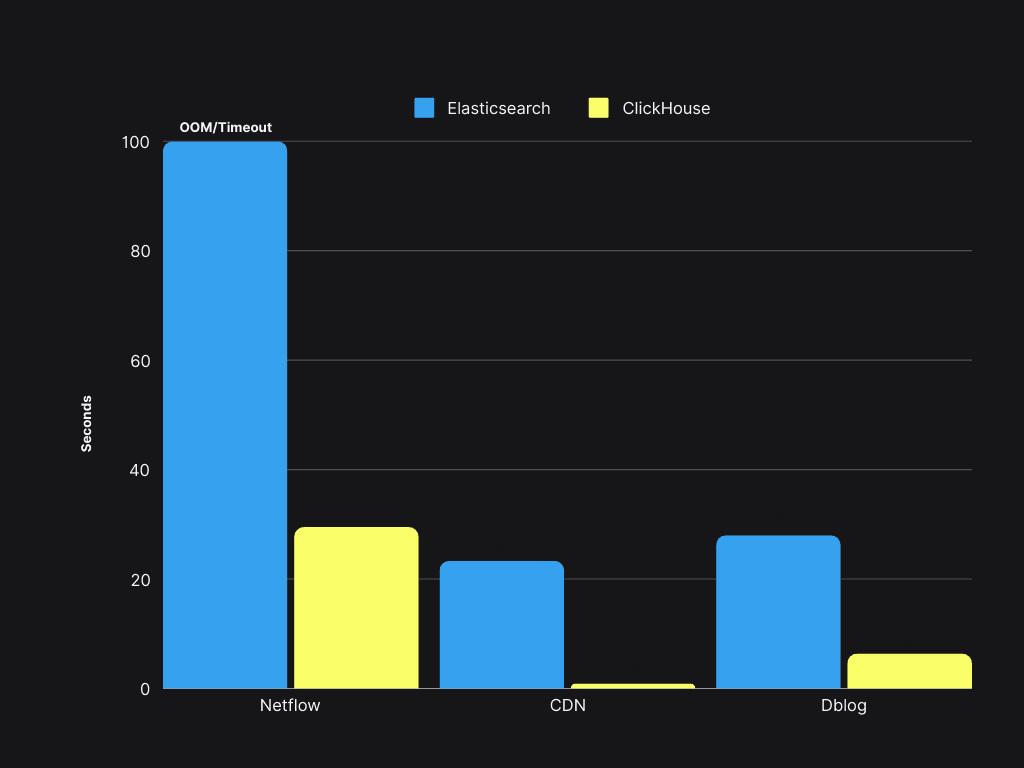
现在一切都已迁移完毕,是时候看看我们平台的新性能了!尽管我们自动化了 95% 的迁移并实现了无缝过渡,但回顾我们的成功指标并查看新平台的表现仍然很重要。两个最重要的指标是查询性能和总体拥有成本(TCO)。
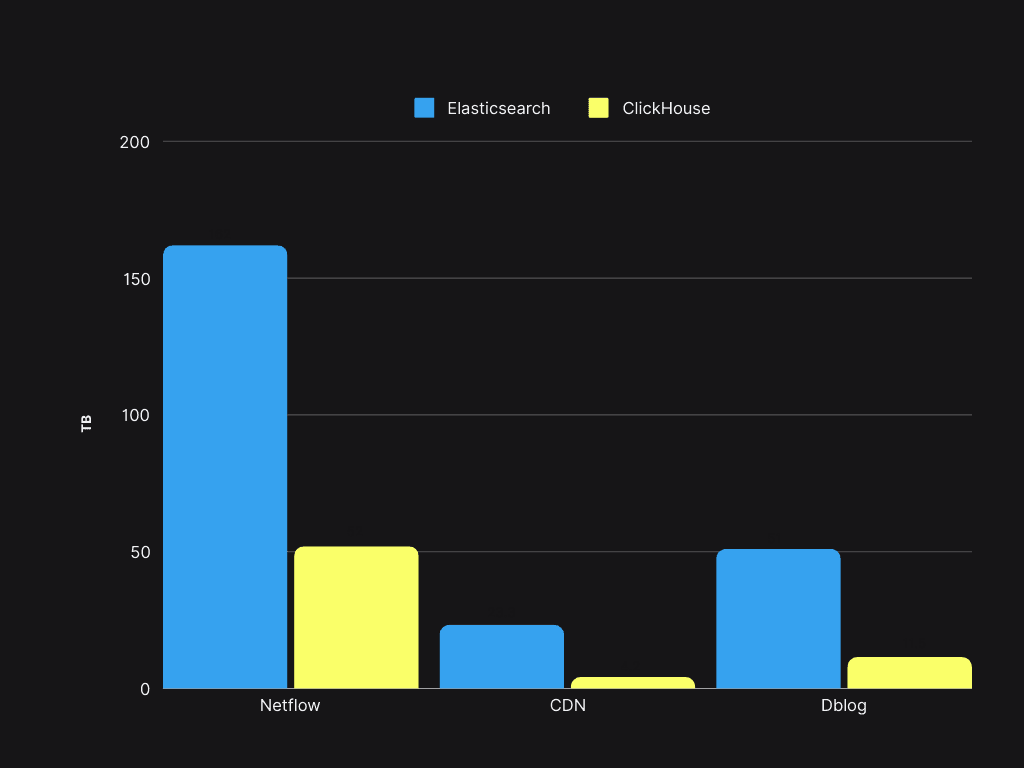
我们最初成本的一个重要组成部分是存储。让我们比较一下 Elasticsearch 和 ClickHouse 在相同数据样本上的存储情况:
存储空间节省超过 50%,使现有的 Elasticsearch 服务器能够支持 4 倍的数据量增加。
查询速度比 Elasticsearch 快 4 到 30 倍,P90 小于 300 毫秒,P99 小于 1.5 秒。
|






















版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。