ClickHouse 是2016年开源的用于实时数据分析的一款高性能列式分布式数据库,支持向量化计算引擎、多核并行计算、高压缩比等功能,在分析型数据库中单表查询速度是最快的。2020年开始在滴滴内部大规模地推广和应用,服务网约车和日志检索等核心平台和业务。本文主要介绍滴滴日志检索场景从 ES 迁移到 CK 的技术探索。
背景
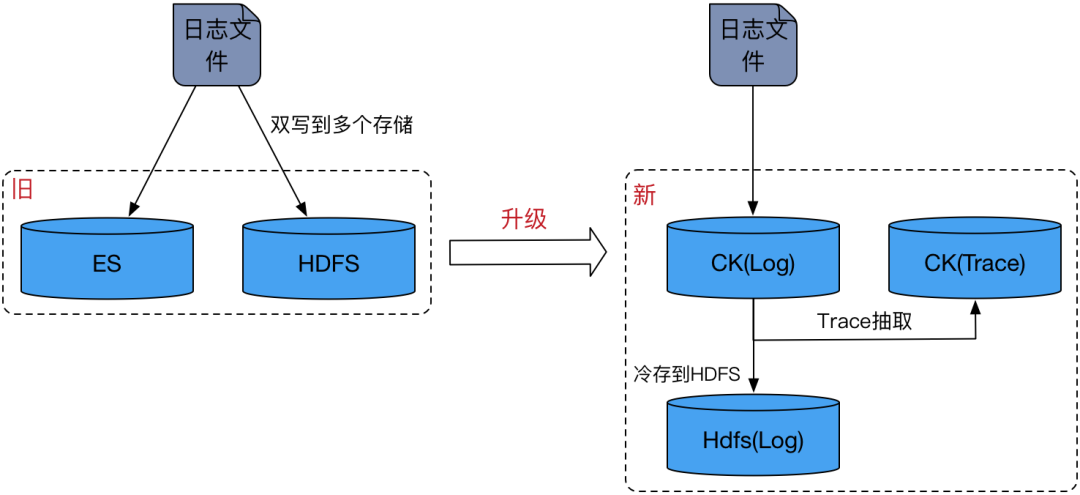
此前,滴滴日志主要存储于 ES 中。然而,ES 的分词、倒排和正排等功能导致其写入吞吐量存在明显瓶颈。此外,ES 需要存储原始文本、倒排索引和正排索引,这增加了存储成本,并对内存有较高要求。随着滴滴数据量的不断增长,ES 的性能已无法满足当前需求。
在追求降低成本和提高效率的背景下,我们开始寻求新的存储解决方案。经过研究,我们决定采用 CK 作为滴滴内部日志的存储支持。据了解,京东、携程、B站等多家公司在业界的实践中也在尝试用 CK 构建日志存储系统。
存储设计是提升性能最关键的部分,只有经过优化的存储设计才能充分发挥 CK 强大的检索性能。借鉴时序数据库的理念,我们将 logTime 调整为以小时为单位进行取整,并在存储过程中按照小时顺序排列数据。这样,在进行其他排序键查询时,可以快速定位到所需的数据块。例如,查询一个小时内数据时,最多只需读取两个索引块,这对于处理海量日志检索至关重要。
以下是我们根据日志查询特性和 CK 执行逻辑制定的存储设计方案,包括 Log 表、Trace 表和 Trace 索引表:
 admin
发表于 2024-10-15 15:07
admin
发表于 2024-10-15 15:07