用 LlamaIndex 和 ClickHouse 为Hacker News 和 Stack Overflow 构建聊天机器人 ...
 admin
发表于 2024-10-15 15:01
admin
发表于 2024-10-15 15:01|
Hacker News 和 StackOverflow 上包含大量关于开发者工具动态的数据,无论是让人么感到兴奋的某些事物,还是他们遇到的问题。虽然这些工具是以帖子为基础使用的,但如果将所有数据都聚合在一起,它们将为您提供关于开发者生态系统的很好概况。作为这两个工具的热心用户,我们想知道诸如以下问题的答案: “对于在1000多员工的组织中工作的人们而言,他们在最想使用的基础设施工具方面,主要的观点是什么?” 在本博客文章中,我们将构建一个名为“HackBot”的基于LLM的聊天机器人,通过使用 ClickHouse、LlamaIndex、Streamlit 和 OpenAI 来回答这些问题。您将学习如何:
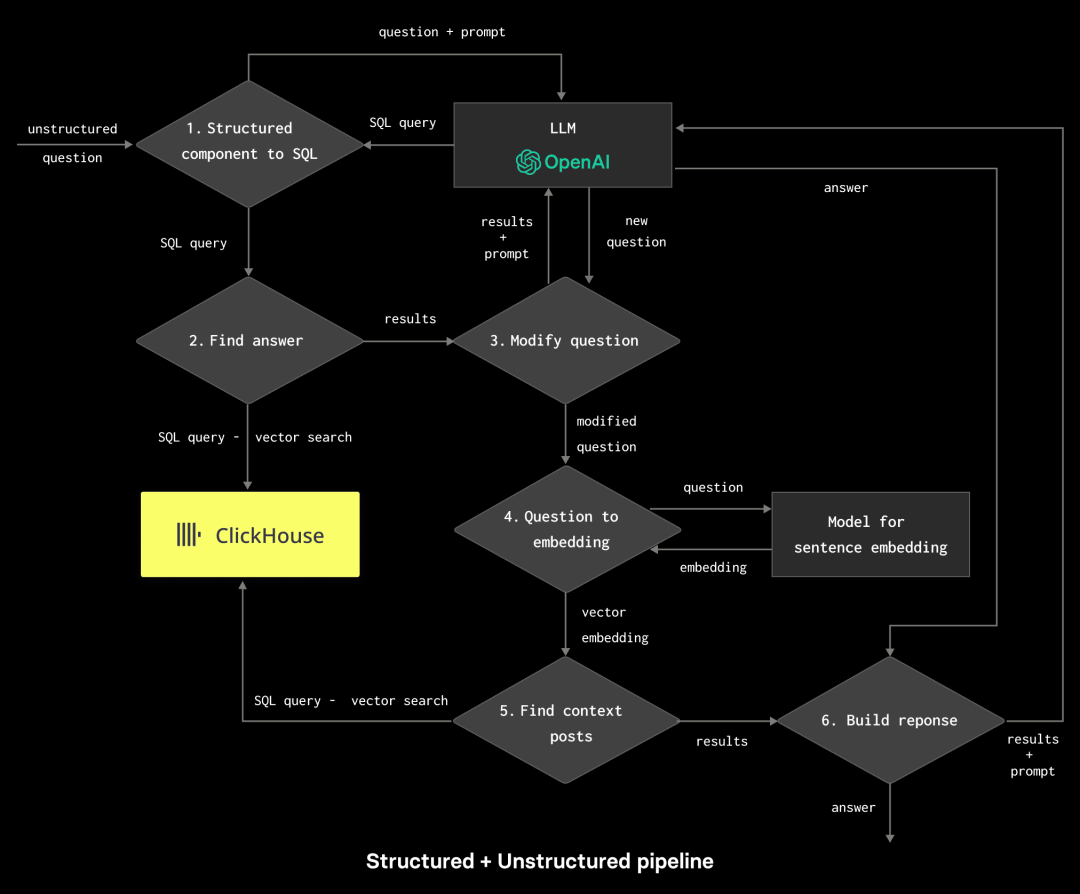
去年,我们探索了:当用户需要用高性能线性扫描,来获得准确结果和/或能够将向量搜索与元数据过滤和聚合结合使用时,ClickHouse 如何作为向量数据库使用。用户可以利用这些功能,通过 Retrieval-augmented generation (RAG) 管道为 LLM 应用提供上下文。随着我们在支持向量搜索的底层支持的持续投入,我们意识到,支持用户构建依赖向量搜索的应用程序也需要投资于周围生态系统。 本着这一精神,我们最近在 LlamaIndex 中添加了对 ClickHouse 的支持,并增强了 Langchain 对 ClickHouse 精确匹配和模板的支持,以简化入门体验。 作为改进这些集成的一部分,我们还花了一些时间将它们付诸实践,并构建了一个名为 HackBot 的应用程序。此应用程序将基于 LlamaIndex。特别是,我们将使用 ClickHouse 和 LlamaIndex 的组合,将 SQL 表中的结构化结果与对 Hacker News 的非结构化向量搜索相结合,以为 LLM 提供上下文。 如果您好奇,我们如何在不到两百行代码的情况下构建了以下内容(提示:Streamlit 在这里有所帮助),请继续阅读,或直接在这里阅读代码【https://github.com/ClickHouse/examples/tree/main/blog-examples/llama-index/hacknernews_app】…
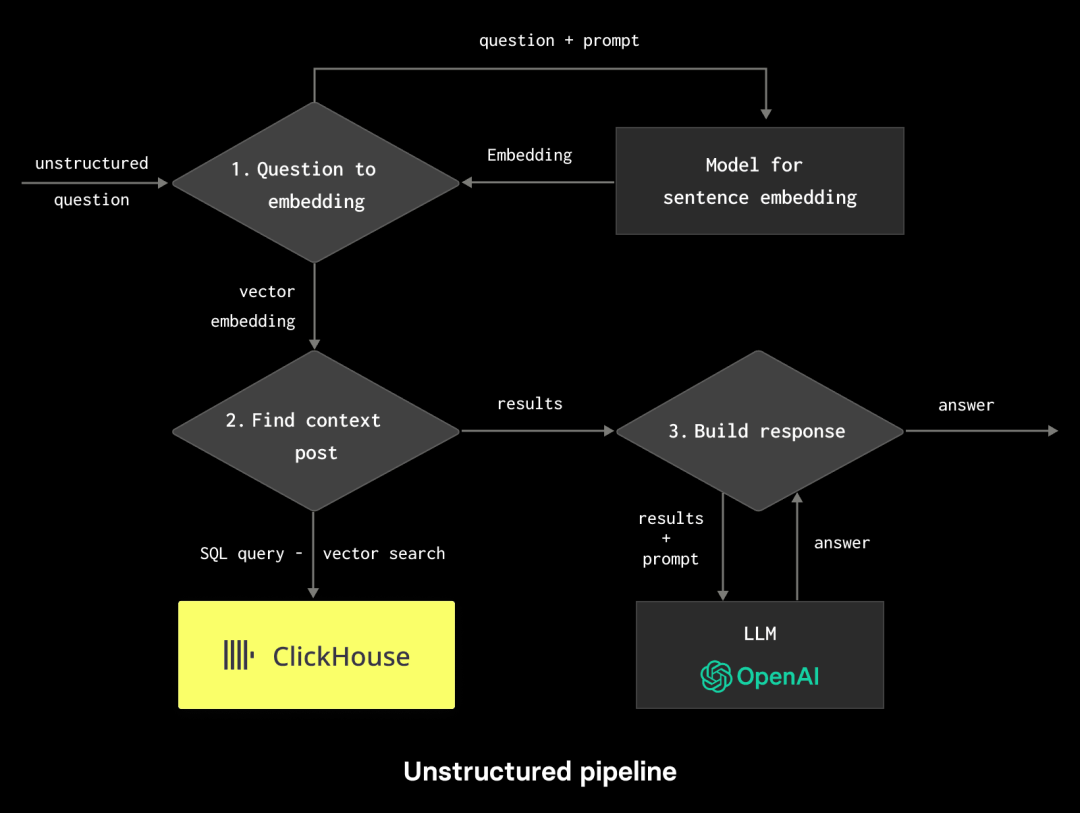
我们在之前的帖子中讨论了检索增强生成(RAG)的概念,以及这种技术如何旨在将预训练的语言模型的强大功能与信息检索系统的优势结合起来。这里的目标通常很简单:通过向模型提供从其他来源(通常通过向量搜索获取)获得的额外信息(上下文),来提高生成文本的质量和相关性。 虽然理论上用户可以手动构建这些 RAG 流程,但 LlamaIndex 提供了一个灵活的数据框架和工具包,用于将数据源连接到大型语言模型。通过将许多现有工作流程作为函数库提供,并支持向几乎任何数据存储插入数据和查询数据,开发人员可以专注于对结果质量产生影响的系统组件,而不是担心应用程序的“粘合-组合方式”。在本博客文章中,我们将使用 LlamaIndex 的查询接口来保持代码的最小化。
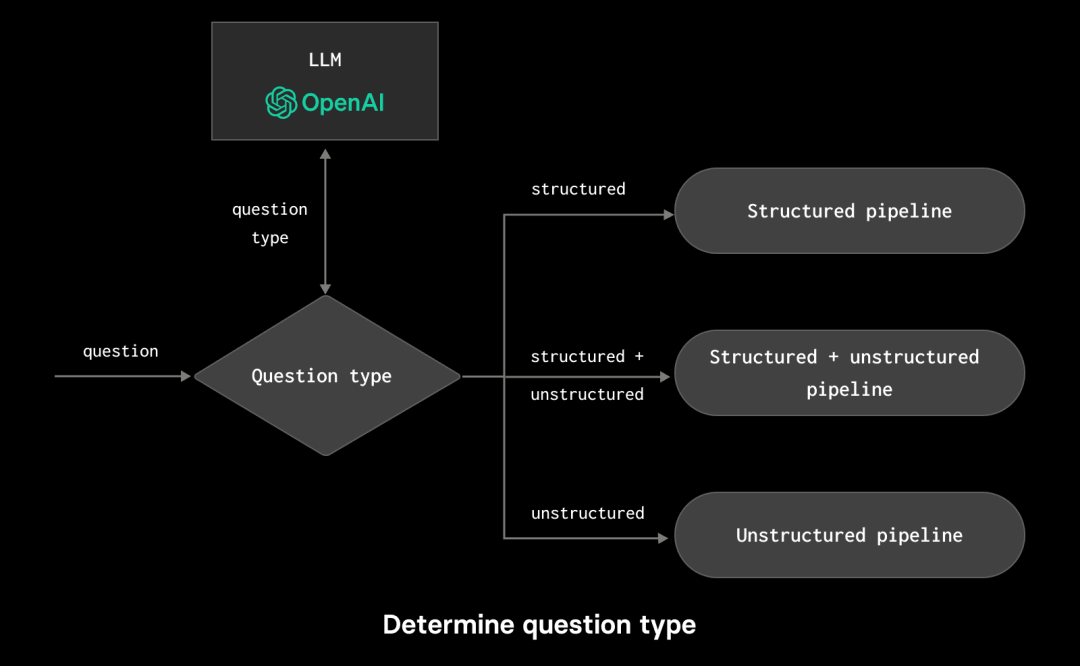
为了说明 LlamaIndex 的好处,让我们考虑一下我们的应用程序“HackBot”。这将接受旨在获取有关 Hacker News 和 Stack Overflow 所进行过的调查中,人们意见摘要的问题。在我们的概念验证中,这些问题将采用三种一般形式:
支持这些需求会导致一个相当复杂的 RAG 流程,其中每个流程包含多个决策点:
通过使用 ClickHouse,我们的问题得到了简化,它可以作为结构化信息(调查)的源,并通过向量搜索作为非结构化信息的源。然而,通常情况下,这将需要大量的应用程序粘合和测试,从确保提示有效到在决策点解析响应。 幸运的是,LlamaIndex 允许将所有这些复杂性封装起来,并通过一组现成的库调用来处理。 数据集 任何良好的应用程序首先需要数据。如前所述,我们的 Hacker News(HN)和 Stack Overflow 帖子代表了我们的结构化和非结构化数据,将为我们的应用程序提供信息支持。我们的 Hacker News 数据包含了超过 2800 万行和 NGiB,而 Stack Overflow 则小得多,仅有 83439 个响应。 我们的 Hacker News 行包含了用户的评论和相关的元数据,例如发布时间、用户名和帖子的分数。文本已经使用 sentence-transformers/all-MiniLM-L6-v2 进行了嵌入,以产生一个 384 维度的向量。这导致以下数据结构:
元数据列包含了可以被 LlamaIndex 工作流自动查询的字段,例如,如果它们确定需要其他过滤器来回答问题。对于我们目前的实现,我们使用一个包含 JSON 的字符串作为此列。将来,一旦生产环境准备就绪,我们计划将其移到 JSON 类型以获得更好的查询性能。目前,我们将所有列复制到此字符串中,从而使它们可供 LlamaIndex 使用,例如: 如果您想测试本文的流程,我们已将所有数据放入了一个 S3 存储桶中的 Parquet 文件中。您可以通过运行以下命令将数据插入:
LlamaIndex在Python和Typescript中都可用。对于我们的示例,我们将使用Python,原因仅仅是我更喜欢它:) 我们不打算一次构建整个RAG流水线,而是首先组装一些基本组件:为结构化和非结构化查询测试一个单独的查询引擎。
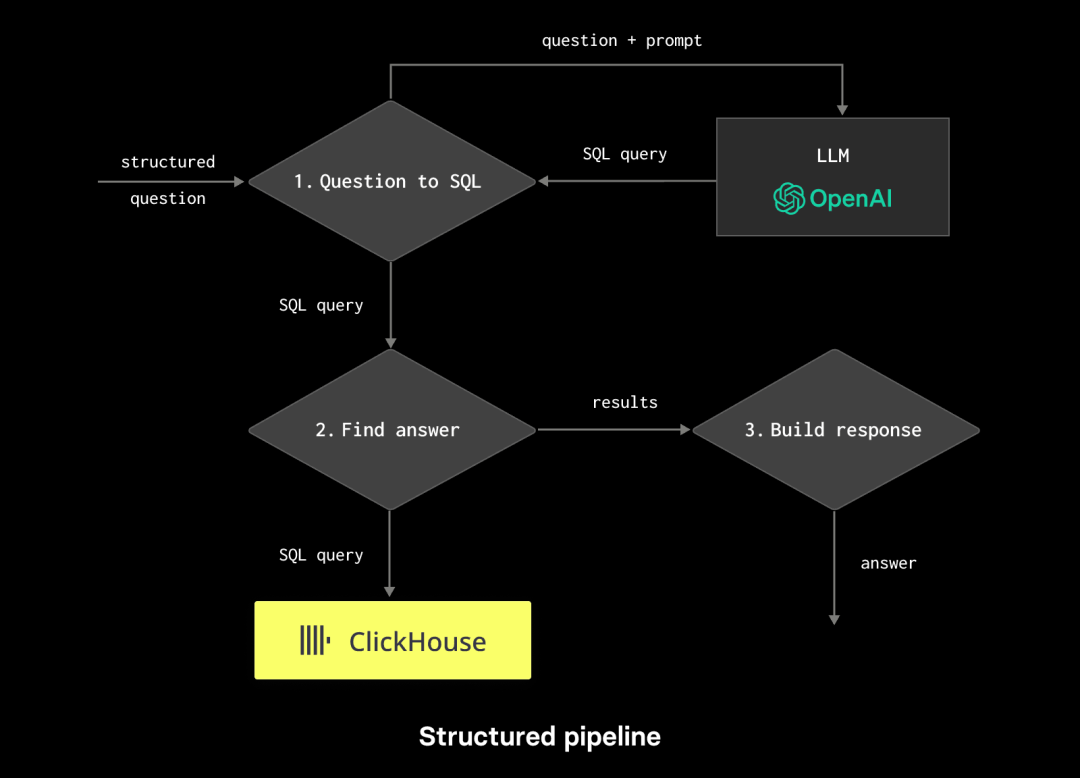
使用LlamaIndex生成SQL 如上所述,我们需要将一些问题转换为针对我们的Stack Overflow数据的SQL查询。我们不会构建一个包含我们数据结构的提示,发出HTTP请求到ChatGPT,然后解析响应,而是可以依靠LlamaIndex进行这个操作,只需进行几次调用即可。以下 Python笔记本在此处可见(https://github.com/ClickHouse/examples/blob/main/blog-examples/llama-index/hacknernews_app/structured_nl_to_sql.ipynb)。
以上输出显示MySQL是最受欢迎的数据库(根据2021年Stack Overflow的数据!):
|











版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。