ClickHouse 的第一篇 研究论文:如何让现代数据分析数据库实现超高速性能? ...
 admin
发表于 2024-10-15 10:35
admin
发表于 2024-10-15 10:35|
PyPi (Python Package Index) 是 Python 编程语言的核心软件仓库,每天有接近 20 亿次下载,使其成为 Python 生态系统中不可或缺的一部分。 虽然这些下载元数据可以通过 BigQuery 进行查询,但对于那些希望深入了解自己喜欢的软件包的用户来说,这种方式仍显得局限。为了满足这一需求,我们创建了 ClickPy。 ClickPy 是一个基于 ClickHouse 的免费服务,允许用户实时分析 PyPi 软件包的下载数据。该项目的代码是开源的,任何人都可以在 GitHub 上获取并在本地运行。
自 9 个月前上线以来,ClickPy 的主表已经突破了 1 万亿行,记录了全球范围内各类库的 1 万亿次下载数据。 接下来,我们将分享 ClickPy 的构建过程,以及如何应对如此庞大的数据集。
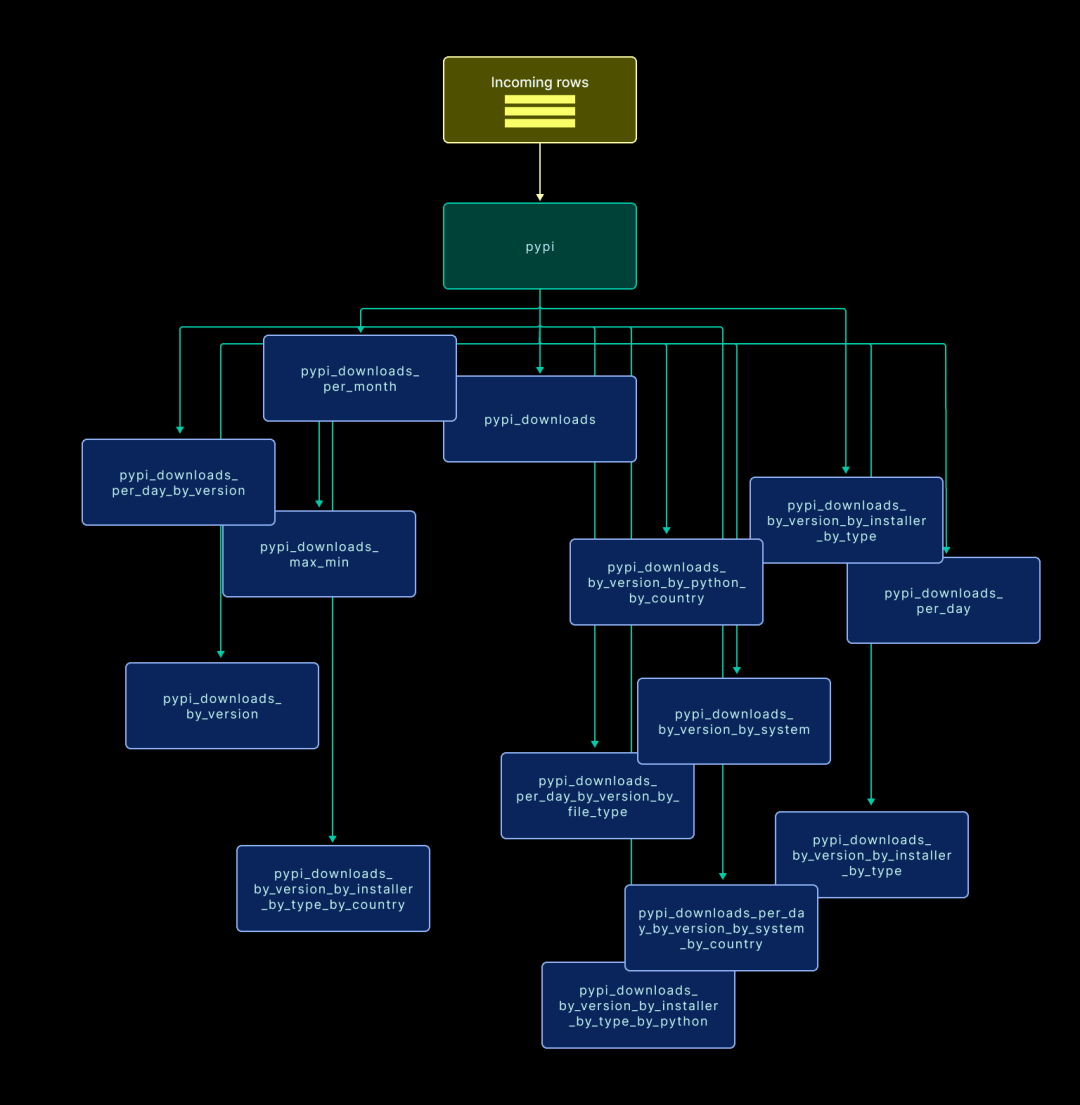
这个项目涉及三个主要实体: 1. 国家 - 包含国家名称和代码等基本信息。 2. 项目 - 每个 PyPi 项目的相关元数据。 3. 下载 - 记录每次项目安装的元数据。 我们将为这些实体分别创建三个表,命名为 countries、projects 和 pypi。 由于 pypi 表记录了每次下载的信息,数据量极为庞大!为优化查询性能,我们将根据常见的查询模式创建多个下游表,并使用预计算视图(Materialized Views)来填充这些表。下图展示了我们将要创建的所有表及其关联:
此外,ClickHouse 还支持字典功能,这是一种内存中的键值对结构,特别适合用于引用数据。我们会为国家创建一个字典,将国家代码映射到国家名称,并为项目创建另一个字典,将项目名称映射到最后更新时间。
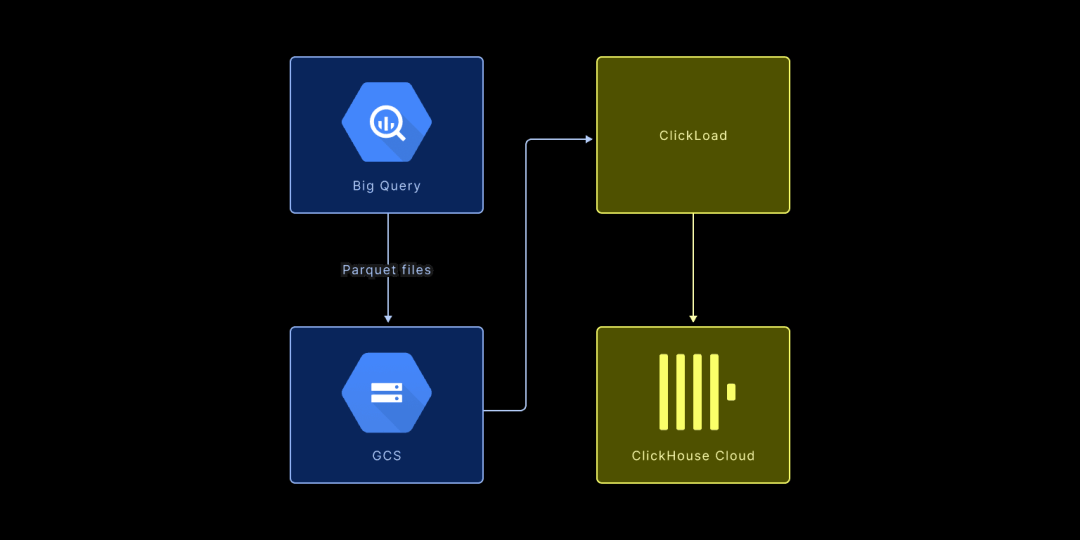
我们将项目和下载数据存储在 BigQuery 中。但由于导出这些数据需要数小时,因此我们将数据导出到 Google Cloud Storage 中,存储为 Parquet 文件。相关查询可以在 ClickPy 的 GitHub 仓库中找到。 接着,我们将数据导入到两个表:projects 和 pypi。虽然不在这里详细讨论表的创建查询,但你可以在指定文件中找到所有相关 SQL 查询【https://github.com/ClickHouse/clickpy/blob/a2d71004cb30e67c703741e50ccb6d8b1d0a0066/ClickHouse.md?plain=1#L471】。 为了导入项目数据,你可以使用以下 SQL 查询:
而对于下载数据,则需要使用以下 SQL 查询:
我们使用了特定脚本来加载前 6000 亿行数据。之后,我们设置了一个每小时运行一次的 cron 作业,它会提取自上次运行以来新增的数据行,并将它们导出为 Parquet 文件。然后,工作线程会处理这些 Parquet 文件,并将数据导入 ClickHouse。这个数据导入工具叫做 ClickLoad,更多细节可以参考相关博客文章【https://clickhouse.com/blog/supercharge-your-clickhouse-data-loads-part3】。
最后,我们还需要导入一个包含国家信息的 CSV 文件,使用以下 SQL 查询即可完成数据导入:
我们来看一下如何使用物化视图从 pypi 表填充下游表。在 ClickHouse 中,物化视图是一种 SQL 查询,当上游表插入新数据时会自动执行。
在建模部分提到的每个下游表,都有对应的物化视图来处理数据填充。
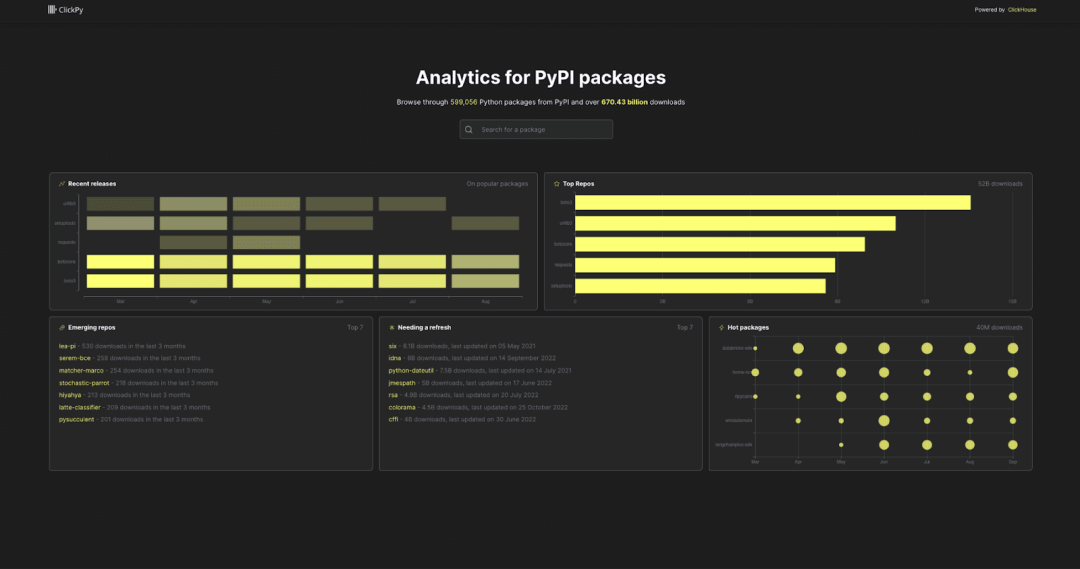
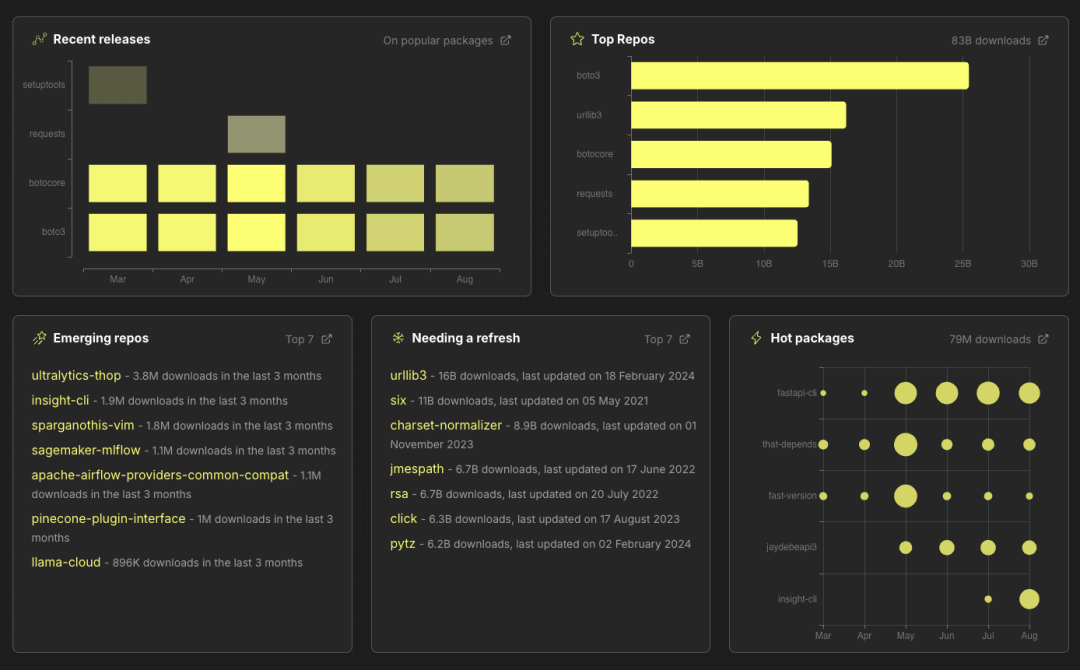
ClickPy 的前端采用 Next.JS 和 React 构建,代码已在 GitHub 上开源【https://github.com/ClickHouse/clickpy/tree/main/src】。 主页展示了所有页面的概览,包括新兴仓库、长期未更新的热门仓库、最新发布的版本等。你可以点击任意项目链接查看详情:
你也可以通过搜索栏查找你喜欢的项目。
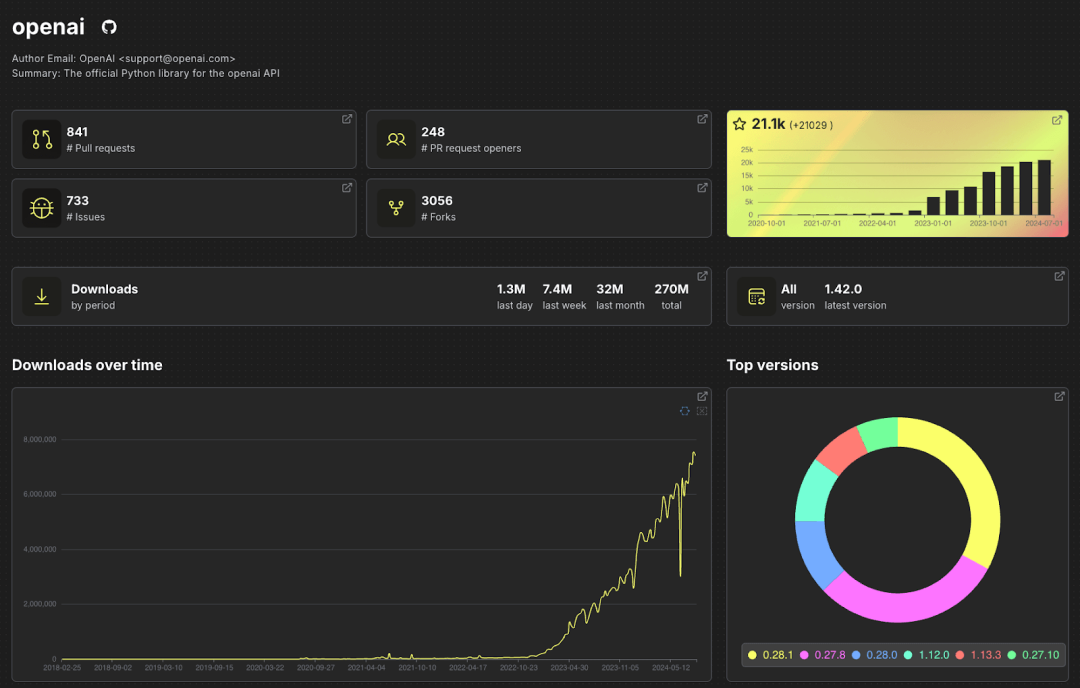
我们以 openai 库为例,这个库与 OpenAI 的 API 进行交互。如果搜索 openai 并点击第一个结果,将会看到以下页面:
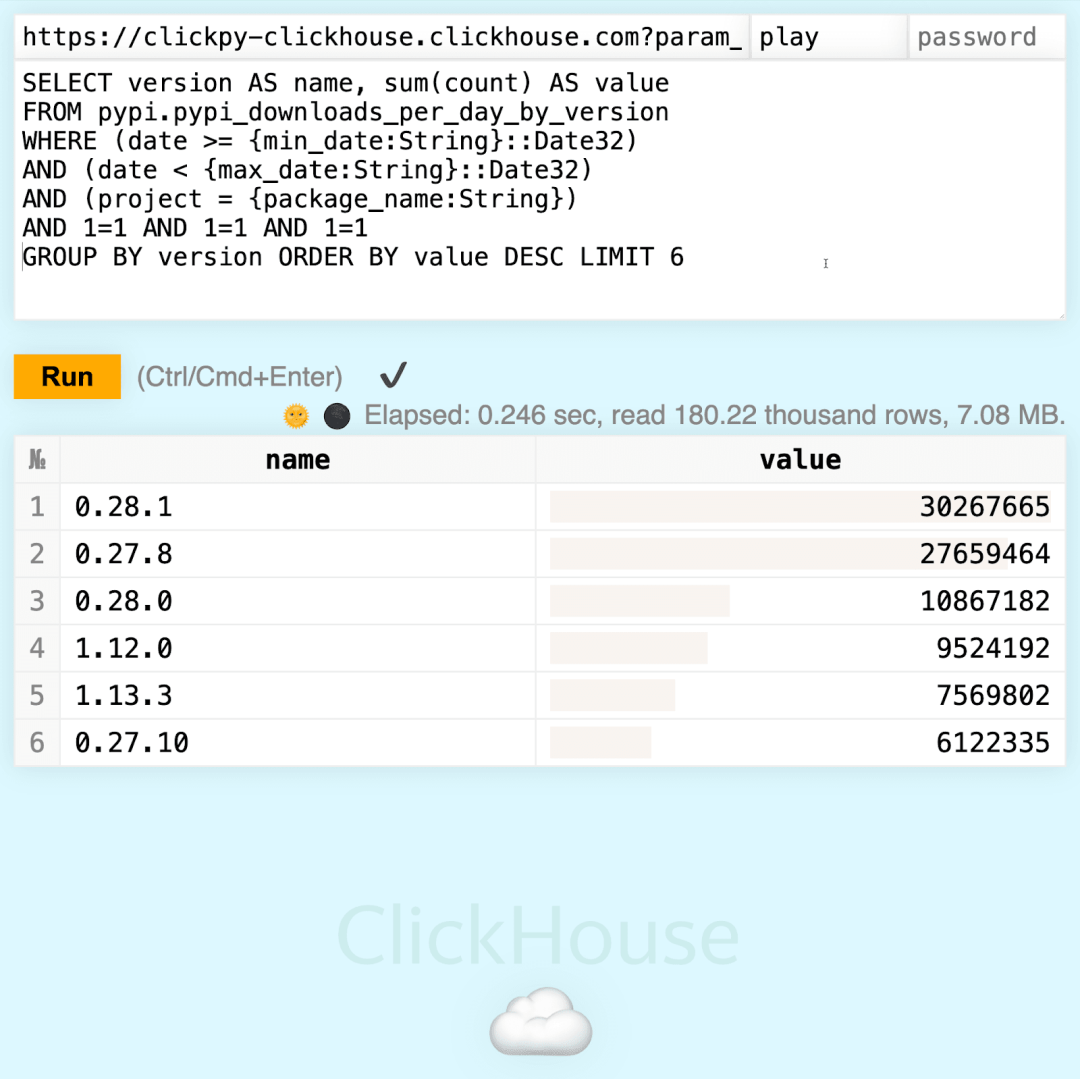
页面顶部显示了一些从 GitHub 获取的数据,下面是下载统计信息。每个统计小部件都配有一个箭头按钮,点击后会跳转到 Play UI,并预填充对应的 SQL 查询。 例如,当我们选择 "Top Versions" 查询时,会看到如下 SQL 查询:
尽管 OpenAI 库的最新版本是 1.41.0,但更多用户下载的是 2023 年 9 月首次发布的旧版本。
除了使用 Play UI 以外,你还可以使用 ClickHouse 客户端,通过只读用户 play user 直接连接数据库进行查询。
运行以下命令即可查看可用的表列表:
每个查询最多允许读取 100 亿行数据,因此不建议直接查询 pypi 表,因为很可能会超过此限制。 其他表的行数相对较少,例如,你可以编写如下 SQL 查询,统计过去 10 天内 pandas 的下载次数,并生成柱状图:
可以看到,尽管周末下载量明显下降,但总体上每天的下载量稳定在 900 万次左右。
更多的数据将被持续导入!自从突破 1 万亿行的里程碑后,又新增了 360 亿行数据。 我们期待你加入 ClickPy 项目。如果你在使用中发现问题或有改进建议,请在项目页面上提出【https://github.com/ClickHouse/clickpy/issues/58】。 如果你基于这些数据开发了任何工具或应用,欢迎在 Twitter 上 @clickhousedb 标记我们,我们将为你推广。 试用阿里云 ClickHouse企业版 轻松节省30%云资源成本?阿里云数据库ClickHouse架构全新升级,推出和原厂独家合作的ClickHouse企业版,在存储和计算成本上带来双重优势,现诚邀您参与100元指定规格测一个月的活动,了解详情:https://t.aliyun.com/Kz5Z0q9G
征稿启示 面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com
我们非常激动地宣布,第一篇关于 ClickHouse 的研究论文【chrome-extension://mhnlakgilnojmhinhkckjpncpbhabphi/pages/pdf/web/viewer.html?file=https%3A%2F%2Fwww.vldb.org%2Fpvldb%2Fvol17%2Fp3731-schulze.pdf】已成功被 VLDB 接收并发表【https://www.vldb.org/pvldb/volumes/17/#issue-12】。 VLDB(国际大规模数据库会议)是全球数据管理领域的顶级会议之一。在数百篇投稿中,VLDB 的录取率通常只有约 20%。 今年的 VLDB 2024 【https://vldb.org/2024/】在中国广州举行,恰逢会议创办 50 周年,成为历史最悠久的数据管理学术会议之一。
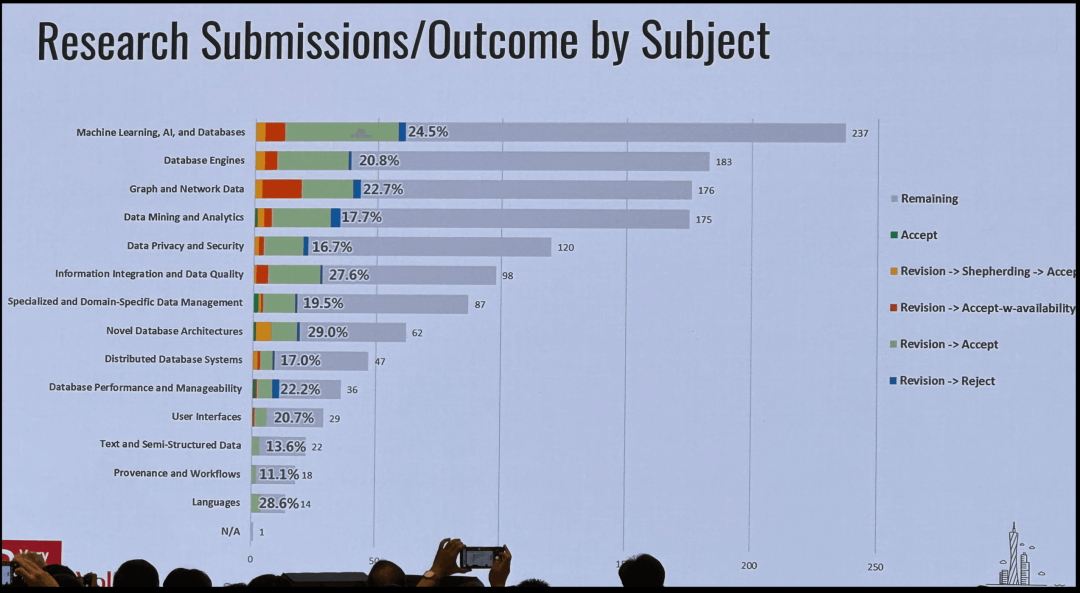
本次会议展示了 250 篇研究论文,并举办了 10 场研讨会,涵盖最新的研究成果和行业发展趋势。 今年的主导话题是各种形态的机器学习,但在数据库核心领域,例如查询引擎、存储技术和数据库理论等方面,依然有大量的研究论文亮相。
这篇论文是历时数月、多个团队合作的成果,向读者介绍了 ClickHouse 在架构和系统设计上独具特色的亮点,让它成为一款超高速数据库。现在,这篇论文首次公开发布! 在论文中,您将了解到: ClickHouse 的发展历程 我们介绍了文中提到的主要功能是什么时候引入的,以及未来将有哪些新功能和改进。
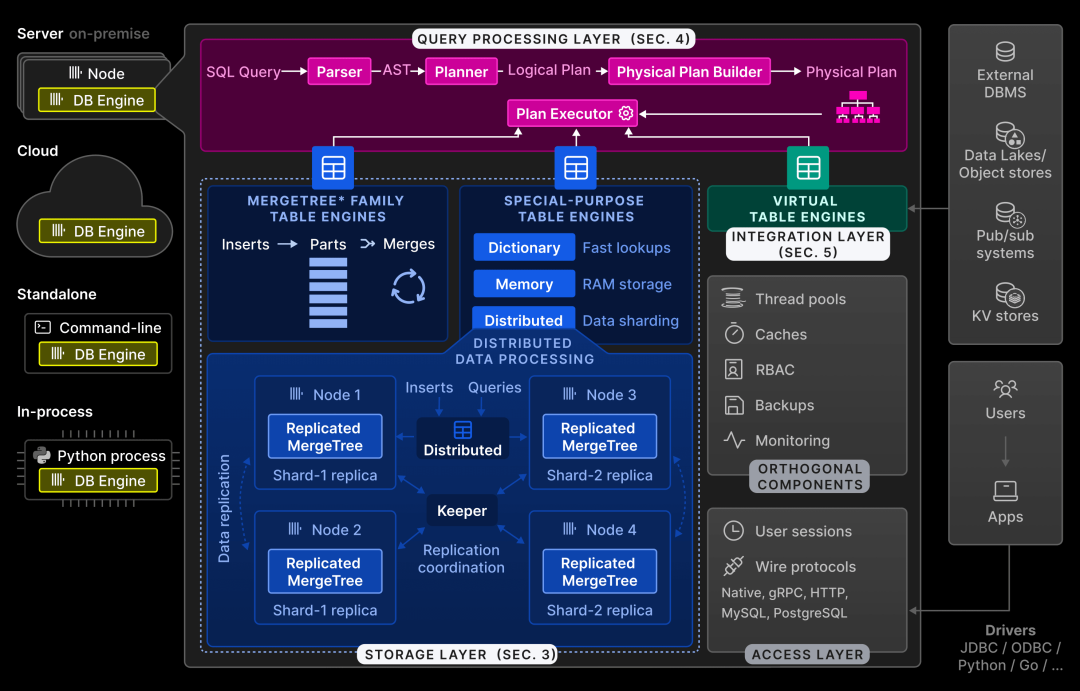
ClickHouse 的架构设计 包括其架构层次、核心组件和不同的执行模式。
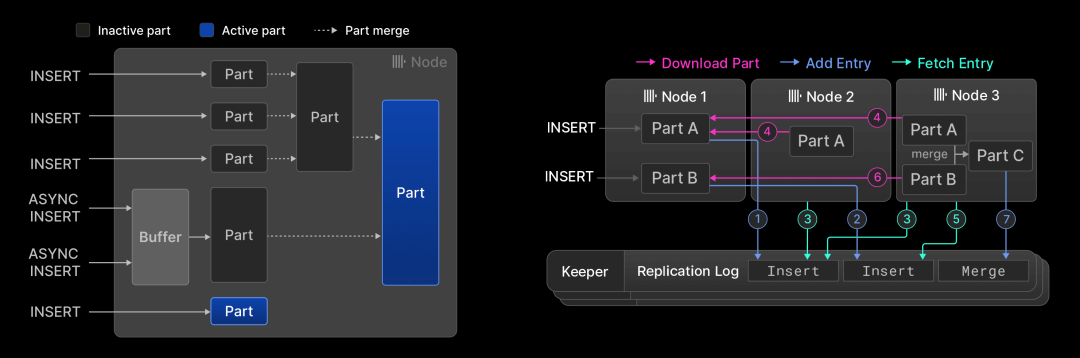
ClickHouse 的存储机制 介绍了磁盘存储格式、数据剪枝技术、数据合并时的转换、更新与删除、幂等插入、数据复制以及 ACID 合规性等。
ClickHouse 的查询处理 涵盖了 SIMD 并行化、多核并行化、多节点并行化及其性能优化技术。
|


















版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。