一文教你使用ClickHouse的字典(dictionary)
 admin
发表于 2024-6-21 20:56
admin
发表于 2024-6-21 20:56|
在本文中,我们将借此机会提示用户:字典在加速查询方面的强大作用 - 尤其是包含JOIN的查询,以及一些使用技巧。此外,本文中的所有示例都可以在我们的play.clickhouse.com环境中复现(参见 blogs 数据库)。
我们原始的表结构是这样的,其中记录了100多年的天气信息:
每一行代表一个时间点的某天气站测量数据 - 每一行有一个 station_id 。利用 station_id 的前两位代表国家代码的事实,我们可以通过知道其前缀并使用子substring函数找到一个国家top 5的温度。例如,葡萄牙:
不幸的是,该查询需要全表扫描,因为它不能利用我们的主键 (station_id, date) 。
我们社区的成员很快提出了一个简单的优化方法,通过减少从磁盘读取的数据量来提高上述查询的响应时间。可以跳过范式设计原则,并在修改成子查询之前,将 station_id单独存储在一个表中来实现。 首先,我们回顾一下这些建议,以便读者理解。下面我们创建一个站点表,并直接通过使用url函数插入数据来填充它。
例如,我们现在假设我们的 noaa表不再有location、elevation和name字段。葡萄牙top 5的温度查询现在几乎可以用子查询解决:
由于子查询利用了 stations 表的 country_code 主键,这样查询更快。此外,父查询也可以使用其主键。只需要读取小范围这些列,从而使磁盘上读取更少的数据,任何连接成本。正如我们社区的成员指出的,这种情况下保持数据反范式是有益的。 但这里有一个问题 - 我们依赖于天气数据上的location和name的反范式。假设我们没有这样做,为了避免重复,并遵循范式原则,并在stations表上分开的原则,我们需要一个full join(实际上,我们可能会保留location和name反范式,并接受存储成本):
遗憾的是,与我们之前的反范式方法相比,这需要全表扫描,所以更慢。这个原因是:
我们还建议字典作为一个可能的解决方案。现在让我们展示一下,在数据已经遵循范式的原则下,我们如何使用字典来提高查询的性能。
字典为我们提供了数据在内存中以键值存储的表示形式,优化了查找查询效率。我们可以利用这种结构来提高查询的性能,特别是当JOIN的一侧是在内存中的查找表时,JOIN查询可以获益。 选择源和键 字典目前可以从两个源填充:本地ClickHouse表和HTTP URLs*。字典的内容可以配置为定期重新加载,以反映源数据中的变化。
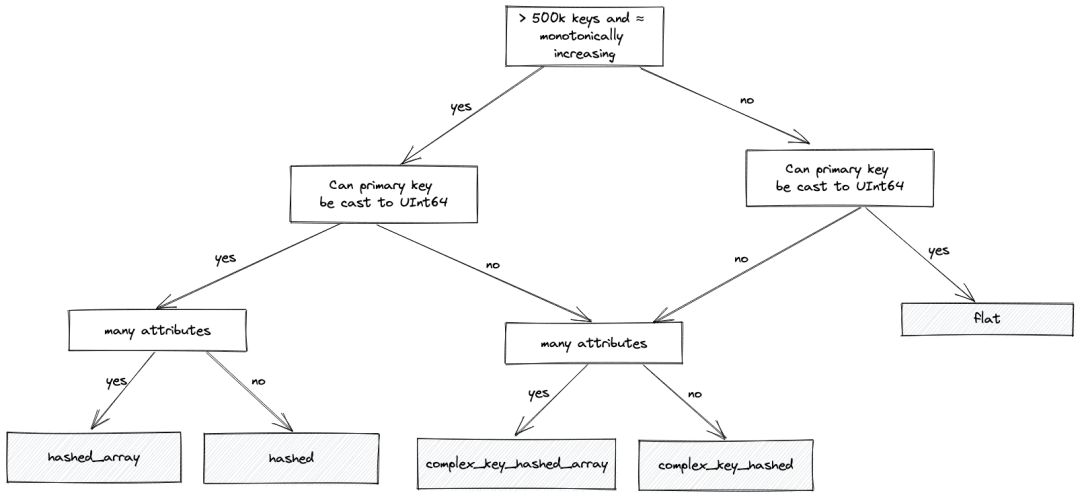
此处的 PRIMARY KEY 是 station_id ,直观地表示将在其上执行查找的列。值必须是唯一的,即具有相同主键的行将被去重。其他列表示属性。您可能已经注意到,我们已经将location分成 lat 和 lon ,因为字典的属性类型目前不支持Point类型。 LAYOUT 和 LIFETIME 不那么显而易见,需要一些解释。 选择布局(layout) 字典的布局控制了它如何存储在内存中以及主键的索引策略。每种布局选项都有不同的优缺点。 flat 类型为最大键值分配一个数组,例如,如果最大值为100k,则数组也将有100k的条目。这非常适合在源数据中有一个单调递增的主键。在这种情况下,它使用非常少的内存,并提供比基于哈希的替代方案快4-5倍的访问速度 - 只需要一个简单的数组偏移查找。但是,它的限制在于键大小也不能超过500k - 尽管这可以通过设置 max_array_size 来配置。对于比较大的稀疏分布,它本质上效率较低,在这种情况下也浪费内存。 对于您有非常大量的条目,大的键值和/或值的稀疏分布的情况,那么 flat 布局变得不那么理想。那么,我们通常会推荐基于哈希的字典 - 特别是 hashed_array 字典,它可以有效地支持数百万条目。这种布局比 hashed 布局更节省内存,而且几乎同样快。对于这种类型,只有一个哈希表用于存储主键,值提供特定属性数组中的偏移位置。这与hashed布局形成对比,尽管会稍微快一点,但需要为每个属性分配一个哈希表 - 因此消耗更多的内存。在大多数情况下,我们因此建议 hashed_array 布局 - 尽管用户在只有少数属性的情况下,应该尝试 hashed 。 所有这些类型也要求键可以转换为UInt64。如果不是,例如,它们是字符串,我们可以使用hashed字典的复杂变体: complex_key_hashed 和 complex_key_hashed_array ,来遵循上面相同的规则。 我们尝试使用下面的流程图来演示上述逻辑,以帮助您选择正确的布局(大多数时候):
对于我们的数据,其中主键是String类型的 country_code ,我们选择 complex_key_hashed_array 类型,因为我们的字典在每种情况下都至少有三个属性。 注意:我们还有 hashed 和 complex_key_hashed 布局的稀疏变种。此布局旨在通过将主键分成组并在其中递增范围来实现O(1)时间操作。我们很少推荐这种布局,只有在您只有一个属性时,它才有效。尽管操作是常数时间的,但实际的常数通常高于非稀疏变种。最后,ClickHouse提供了如polygon和ip_trie等专门的布局。 选择生命周期 上面的字典DDL还为字典指定 LIFETIME 。这指定了字典应该多久重新读取源来刷新数据。这可以指定为秒数或范围,例如, LIFETIME(300) 或 LIFETIME(MIN 300 MAX 360) 。在后一种情况下,会选择一个在范围内均匀分布的随机时间。当多个服务器正在更新时,这确保了字典源上的负载随时间分布。我们例子中使用的值 LIFETIME(MIN 0 MAX 0) 意味着字典内容永远不会被更新 - 在我们的情况下很合适,因为我们的数据是静态的。 如果您的数据会被更新,并且您需要定期重新加载数据,则此行为可以通过返回行的invalidate_query参数来控制。如果此行的值在更新周期之间更改,ClickHouse知道必须重新获取数据。例如,这可以返回时间戳或行数。存在进一步的选项,以确保自上次更新以来只加载已更改的数据 - 请参见我们的文档,了解如何使用 update_field 的示例。
尽管我们的字典已经创建,但它需要一个查询来将数据加载到内存中。这样做的最简单方法是发出一个简单的 dictGet 查询来检索单个值(将数据集加载到字典中作为一个副作用)或通过发出明确的 SYSTEM RELOAD DICTIONARY 命令。
上面的 dictGet 示例检索了国家代码 P0 的 station_id 值。 回到我们原来的Join查询,我们可以恢复我们的子查询,并仅为我们的location和name字段使用字典。
|









版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。