深度介绍全排序合并联接、部分合并联接
 admin
发表于 2024-6-21 20:54
admin
发表于 2024-6-21 20:54|
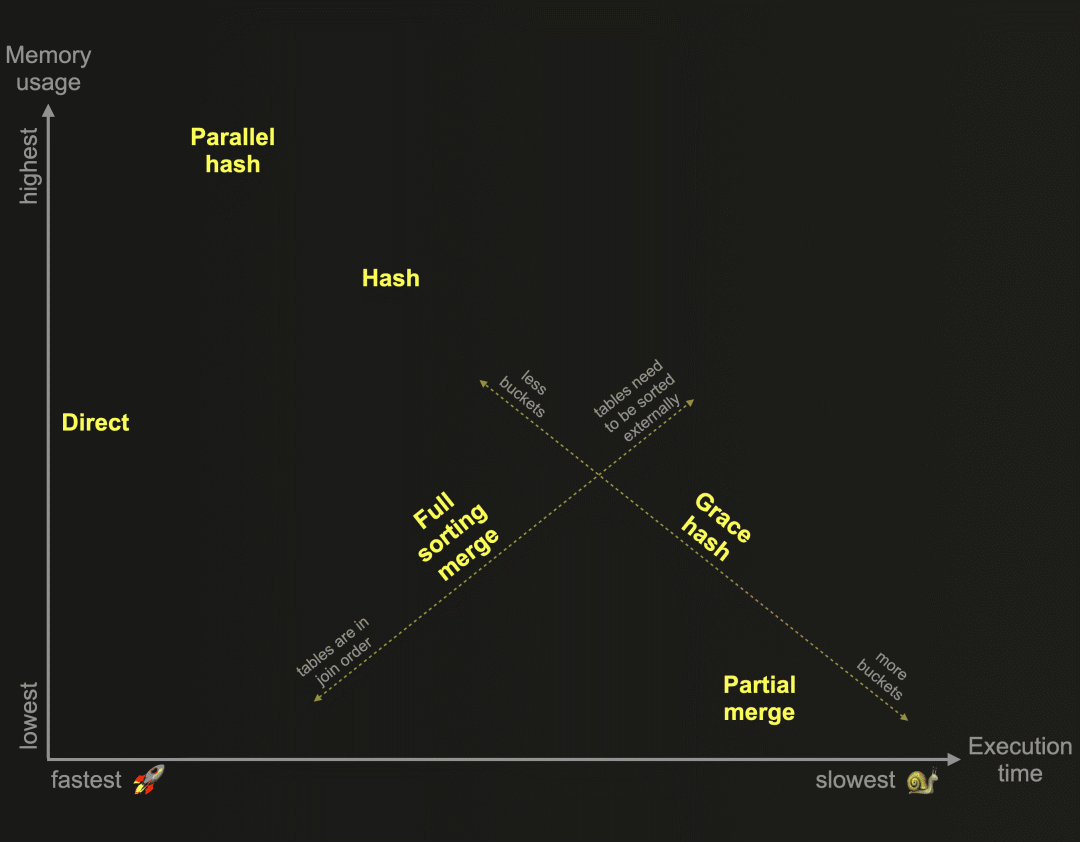
在我们之前的博文中,我们开始探索为ClickHouse开发的6种不同联接算法。作为提醒:这些算法决定了联接查询的计划和执行方式。ClickHouse可以根据资源的可用性和使用情况自适应选择和动态更改运行时使用的联接算法。然而,ClickHouse还允许用户自行指定所需的联接算法。下面的图表基于相对内存消耗和执行时间,概述了这些算法:
提醒一下:哈希联接和并行哈希联接速度快,但受限于内存。右侧表的联接数据需要适应内存。优雅哈希联接是一种非内存受限版本,可以将数据临时溢出到磁盘,而不需要对数据进行排序,因此克服了其他将数据溢出到磁盘并需要先对数据进行排序的联接算法的性能挑战。这让我们来到了这篇博文。
这两种算法都不受内存限制,并使用联接策略,要求联接数据在联接键的顺序中首先进行排序,然后才能识别联接匹配。 完全排序合并联接通过交错线性扫描和合并来联接两个表的行,这些行来自于两个表中的已排序行块的已排序流:
部分排序合并联接通过将左表的每个已排序行块与右表的已排序行块进行合并,来联接两个表的行:
完全排序合并联接可以利用一个或两个表的物理行顺序,从而跳过排序。在这种情况下,联接性能可以与上图中的哈希联接算法竞争,同时通常需要更少的内存。否则,完全排序合并联接需要在识别联接匹配之前完全排序表的行。排序可以在内存中进行(如果数据适合)或在外部磁盘上进行。 部分排序合并联接在处理大表联接时优化了内存使用。右表总是通过外部排序进行完全排序。为了在识别联接匹配时最小化处理在内存中的数据量,特殊的索引结构会在磁盘上创建。左表总是以块为单位在内存中进行排序。但如果左表的物理行顺序与联接键排序顺序匹配,则内存中识别联接匹配更高效。
我们使用与之前的博文中介绍的相同的两个表和ClickHouse Cloud服务实例。 对于所有示例查询运行,我们使用max_threads的默认设置。执行查询的节点有30个CPU核心,因此默认的 max_threads 设置为30。为了使查询管道的可视化简洁和可读,我们通过设置 max_threads = 2 人为地限制了ClickHouse查询管道中使用的并行级别。 现在让我们继续探索ClickHouse来联接算法。
描述 完全排序合并联接算法是集成到ClickHouse查询管道中的经典排序-合并联接。 ClickHouse版本的排序-合并联接提供了几个性能优化。
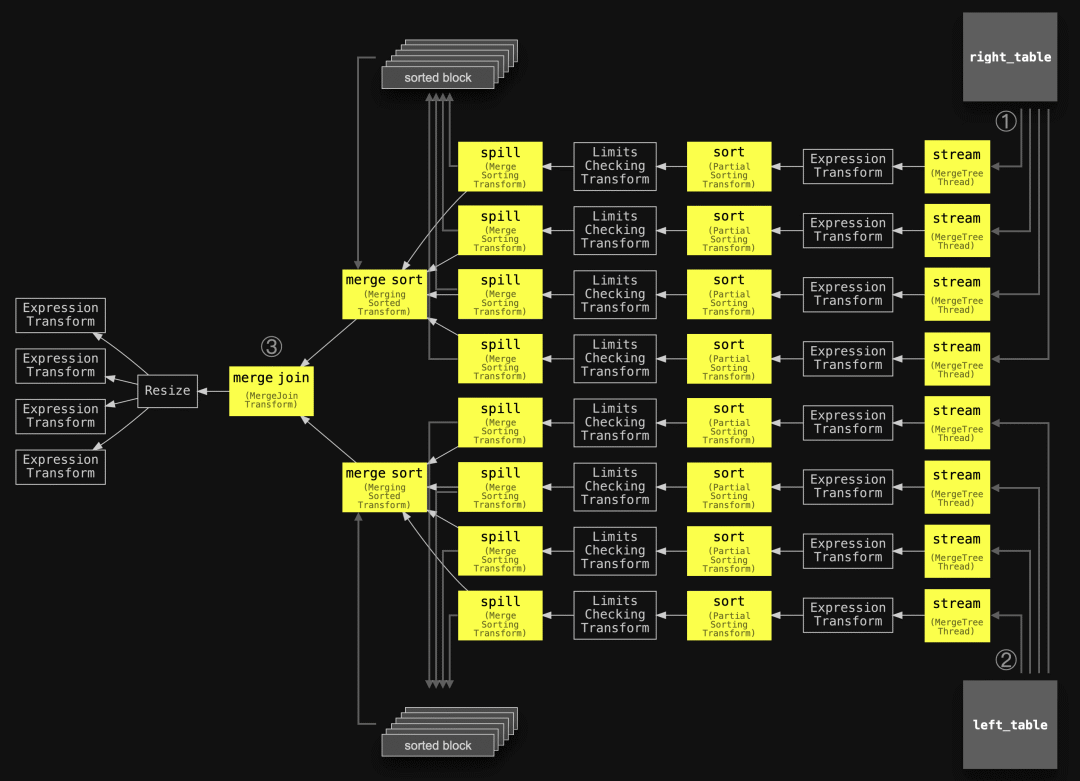
我们将在后面详细讨论这些优化。 下图显示了未应用任何优化的全排序合并联接算法的一般版本:
① 从右表格中的所有数据以块为单位并行地通过2个流式传输阶段(因为 max_threads = 2 )流式传输到内存中。两个并行的排序阶段按联接键列的值对每个流式传输的块中的行进行排序。这些排序后的块通过两个并行的溢出阶段溢出到临时存储中。 ② 与①同时进行,左表格的所有数据以块为单位并行地通过2个线程( max_threads = 2 )流式传输,类似于①,每个块都会进行排序并溢出到磁盘上。 ③ 以每个表格一个流的方式,从磁盘上读取排序后的块,并进行合并排序,通过合并(交替扫描)两个排序流来识别联接匹配项。 支持的联接类型 支持INNER、LEFT、RIGHT和FULL联接类型以及ALL和ANY严格度的所有联接。 示例 为了首先演示未应用任何优化的全排序合并联接算法的一般版本,我们使用一个联接查询,查找在电影中将演员的名字用作角色名的所有演员。通过设置 max_rows_in_set_to_optimize_join=0 ,我们禁用了在联接之前按照联接键过滤联接表的优化操作:
像往常一样,我们可以查询query_log系统表以检查最后一个查询运行的运行时统计信息。请注意,我们使用ProfileEvents列中的一些键来检查在联接处理过程中通过外部排序溢出到磁盘的数据量:
我们可以看到,ClickHouse没有将任何数据溢出到磁盘,并且完全在内存中处理了联接,内存使用峰值为4.71 GiB。 执行上述查询的ClickHouse节点具有可用的120 GiB主内存。
当要排序的数据量超过可用主内存的一半时,ClickHouse会配置为使用外部排序。
我们可以通过在查询的SETTINGS子句中将 max_bytes_before_external_sort 设置为较低的阈值来触发联接示例查询的外部排序:
我们为最好连词的联接示例检查实时统计数据:
我们可以看到,对于使用降低的 max_bytes_before_external_sort 设置运行的查询,使用的内存较少,并且数据溢出到磁盘,表明使用了外部排序。请注意,此查询的 read_rows 指标对于具有外部处理的管道目前不是精确的 查询流水线和追踪日志 如同在本博客系列的前一部分中所做的那样,我们可以使用ClickHouse命令行客户端(快速安装说明在此处)来检查示例联接查询的ClickHouse查询管道(max_threads设置为2)。我们使用EXPLAIN语句来打印用DOT图形描述语言描述的查询管道图,并使用Graphviz dot将图形呈现为PDF格式:
我们使用与上面的抽象图中相同的编号注释了管道,稍微简化了主要阶段的名称,并添加了两个联接的表格以对齐这两个图表:
我们可以看到查询管道与上面的抽象版本相匹配。 请注意,如果要排序的块数据的峰值内存占用量保持在配置的外部排序阈值以下,则会忽略溢出阶段,并且排序后的块会立即进行合并排序和联接。 另请注意,要排序的块数据的峰值内存占用量与两个联接表中的总数据量关系不大,而更多地取决于查询管道内配置的并行级别。在ClickHouse中,数据是流式处理的:数据以并行和块方式流式传输到(内存中的)查询引擎中。流式传输的数据块按顺序和并行方式由特定的查询管道阶段进行处理,因此一旦一些表示(部分)查询结果的块可用,它们就会从内存中流式传输回查询的发送方。 为了观察外部排序和数据溢出到磁盘,我们通过要求ClickHouse在执行期间将跟踪级别的日志发送给ClickHouse命令行客户端,来检查两个示例联接查询运行的实际执行情况。 首先,我们获取降低了外部排序阈值的查询运行的跟踪日志:
在分析上述跟踪日志条目之前,快速提醒一下,我们对所有示例查询运行使用了默认的 max_threads 设置。该设置控制查询管道内的并行级别。执行查询的节点具有30个CPU核心,因此默认的 max_threads 设置为30。为了使查询管道的可视化简洁和可读性好,我们人为地限制了ClickHouse查询管道中使用的并行级别,将设置 max_threads = 2 。 我们可以看到有6个并行流和30个并行流分别用于以块为单位将数据从两个表格流式传输到查询引擎中。这是因为 max_threads 设置为30。请注意,仅使用了6个并行流,而不是30个并行流,用于包含100万行的 actors 表。这是因为设置了merge_tree_min_rows_for_concurrent_read_for_remote_filesystem(对于云端而言,对于OSS而言,设置为merge_tree_min_rows_for_concurrent_read)。该设置配置了单个查询执行线程应该至少读取/处理的最小行数。默认值为163,840行。而1百万行/163,840行=6个线程。对于包含1亿行的 roles 表,结果将为610个线程,超过了我们配置的最大值30个线程。 此外,我们还可以看到MergeSortingTransform(在上面的图表中被简化为'spill')阶段的条目,指示数据(排序后的块的数据)溢出到磁盘上的临时存储中。MergingSortedTransform阶段(在上面的图表中称为'merge sort')的条目总结了从临时存储中读取的排序块的合并排序过程。 最后的MergeJoinAlgorithm条目总结了联接处理过程:来自左表的1百万行以块为单位(通过6个并行流)以16个块的形式流式传输(每个块中约62500行-接近默认块大小)。来自右表的1亿行以块为单位(通过30个并行流)以1529个块的形式流式传输(每个块中约65400行)。在流式处理过程中,在 merge join 阶段同时最多在内存中保存3个具有相同联接键的块中的行。对于我们示例查询中INNER联接的ALL严格性而言,这些行的笛卡尔乘积在内存中完成。 接下来,我们获取没有降低外部排序阈值的查询运行的跟踪日志:
日志条目表明查询执行未触发任何数据溢出到磁盘,因为块数据的内存中峰值体积保持在默认的外部排序阈值以下。因此,溢出阶段被跳过,排序块立即进行了合并排序和联接操作,而无需进行基于磁盘的排序。 扩展 在上一篇文章中,我们解释了 "max_threads "设置可控制查询流水线的并行程度。为了提高可读性,我们人为地限制了查询管道可视化的并行程度,设置为 max_threads=2。 现在我们可以检查 max_threads 设置为 4 的完全排序合并联接查询的查询流程图:
现在每个表都使用了四个并行的流、排序和溢出阶段。这加速了数据块的(外部)排序。然而,每个表的合并排序阶段和最终的合并联接阶段需要保持单线程以确保正确运行。不过,ClickHouse还提供了一些附加的性能优化方法,我们接下来将讨论这些优化方法。 优化 在联接之前,通过使用彼此的联接键值对表进行筛选。 在排序合并联接之前,可以通过彼此的联接键对加入的表进行过滤,以最小化需要排序和合并的数据量。为此,如果可能的话(见下文),ClickHouse会构建一个内存集合,其中包含右表的联接键列的(唯一)值,并使用该集合过滤掉左表中所有不可能有联接匹配的行,反之亦然。如果一张表比另一张表小得多,并且表的唯一联接键列值适合内存,那么这个方法尤其有效。 哈希联接在这种情况下也会表现良好。但是,完全排序合并联接以相同的方式适用于左表和右表,在两个表都大于可用内存的情况下,它将自动回退到外部排序。这种优化是为了将哈希联接的性能带到完全排序合并联接的特定用例中。max_rows_in_set_to_optimize_join设置控制着这种优化。将其设置为0会禁用它。默认值为100,000。该值指定了两个表集合的最大允许大小(按条目计算)。这意味着如果两个集合加在一起仍然低于阈值,则优化将应用于两个表。如果两个集合加在一起超过了阈值,那么仍然可能有一个集合低于阈值,并且优化将仅应用于一个表。正如我们将在下面的跟踪日志中看到的那样,ClickHouse将顺序尝试为两个表构建集合,并在超过限制时进行回退和跳过构建集合。 我们的示例联接查询是通过 first_name 和 role 列进行联接的:
我们检查(较小的)左表中唯一联接键列值的数量:
然后,我们检查(较大的)右表中唯一联接键列值的数量:
使用 max_rows_in_set_to_optimize_join 设置的默认值100,000,该优化不会应用于任何表。 为了演示,我们使用 max_rows_in_set_to_optimize_join 的默认值执行示例查询: |












版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。