ClickHouse 24.12 版本发布说明
 admin
发表于 2025-1-13 17:27
admin
发表于 2025-1-13 17:27|
又到了月度版本更新的时间! 发布概要 ClickHouse 24.12 版本重磅发布,本次更新带来了16项全新功能🦃、16项性能优化⛸️、36个bug修复🏕️ 本次版本新增了多项实用功能,包括改进 Enum 的可用性、支持 Iceberg REST 目录和模式演进、实现反序表排序、支持将 JSON 子列作为主键、自动优化 JOIN 的执行顺序等更多亮点功能!
我们热烈欢迎 24.12 版本中的所有新贡献者!ClickHouse 的成功离不开社区的共同努力。每次看到社区不断壮大,都会让我们倍感激励和鼓舞。 以下是本次版本的新贡献者名单:Emmanuel Dias, Xavier Leune, Zawa_ll, Zaynulla, erickurbanov, jotosoares, zhangwanyun1, zwy991114, JiaQi
贡献者:ZhangLiStar 本次发布改进了 Enum 类型的可用性。我们将通过 Reddit 评论数据集示例来展示这些变化。首先,创建一个包含几个字段的表:
随后,我们可以插入数据,如下所示:
假如我们希望统计 subreddit_type 中包含字符 "e" 的帖子数量,可以使用 LIKE 运算符编写如下查询:
在 24.12 版本之前运行该查询,会显示以下错误信息:
而在 24.12 版本中运行相同的查询,则会返回如下结果:
此外,等号 (=) 和 IN 运算符现在也支持未知值。例如,以下查询会返回类型为 Foo 或 public 的所有记录:
在 24.12 版本之前运行这段查询时,会显示以下错误信息:
而在 24.12 版本中运行该查询,则会返回如下结果:
贡献者:Amos Bird 本次版本新增了一个 MergeTree 设置 allow_experimental_reverse_key,支持在 MergeTree 排序键中启用降序排序。以下是一个简单的示例:
这个表会按照 time 字段进行降序排列。 这种降序排序功能在时间序列分析中非常有用,尤其是处理 Top N 查询时效果显著。
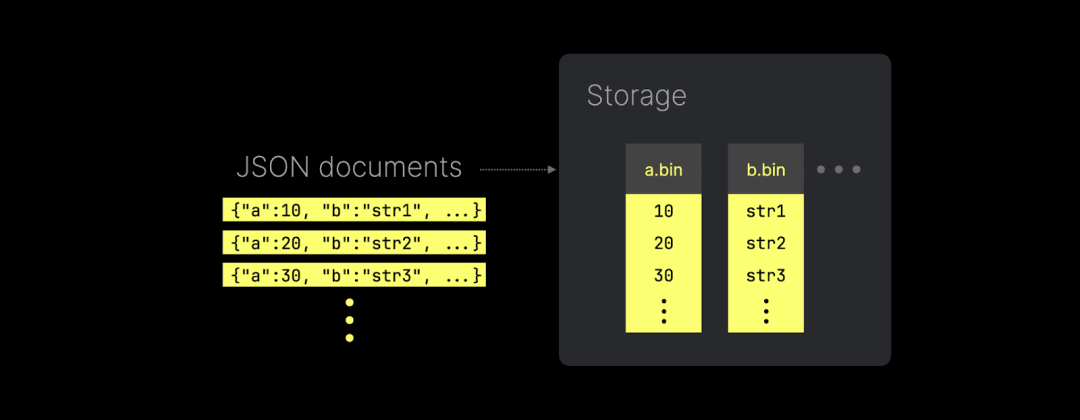
贡献者:Pavel Kruglov ClickHouse 引入了全新的 JSON 实现,可以将每个唯一的 JSON 路径存储为真正的列式数据:
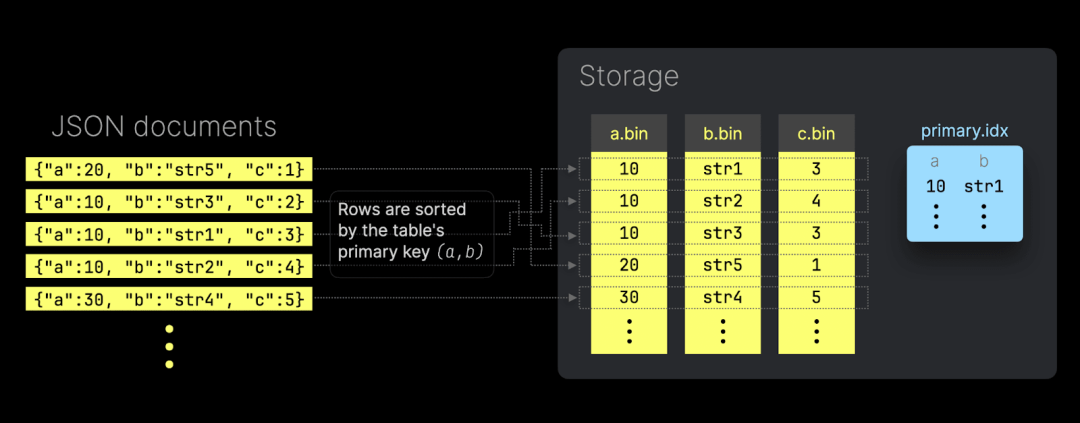
上图展示了 ClickHouse 如何将 JSON 键路径以原生子列的形式存储(并支持读取)。这种方式不仅提供了出色的数据压缩,还能保持与传统数据类型相同的查询性能。 在本次发布中,ClickHouse 现已支持将 JSON 子列用作表的主键列:
这意味着,写入的 JSON 文档会根据用作主键的 JSON 子列,按分片顺序在磁盘上进行排序。此外,ClickHouse 会为这些主键列自动创建主索引文件,从而加速基于主键的过滤查询:
同时,当主键列按基数从低到高排序时,JSON 子列的 *.bin 数据文件也能实现最佳压缩效果。 以下是一个更具体的示例: 测试中我们使用了一台 AWS EC2 m6i.8xlarge 实例,配置为 32 个 vCPU 和 128 GiB 内存,并选用了 Bluesky 数据集。 我们将 1 亿条 Bluesky 事件(每个事件为一个 JSON 文档)加载到两个不同的 ClickHouse 表中。 第一个表没有使用任何 JSON 子列作为主键列:
第二个表则使用了一些 JSON 子列作为主键列(还为部分列添加了类型提示,以避免查询中的类型转换):
这两个表都存储了完全相同的 1 亿条 JSON 文档。 接着,我们在没有主键的表上运行一个查询(查询内容为“人们何时在 Bluesky 上屏蔽他人”,改编自“人们何时使用 Bluesky?”的查询,您可以在 ClickHouse SQL playground 上试运行):
然后,我们在带有主键的表上运行相同的查询(需要注意,该查询对主键列的前缀字段进行了过滤):
Boom!查询速度提升了 50 倍,内存使用减少了 150 倍。
贡献者:Daniil Ivanik 和 Kseniia Sumarokova 在本次版本中,ClickHouse 新增了对 Apache Iceberg REST catalog 查询的支持。目前已支持 Unity 和 Polaris catalog。我们可以通过 Iceberg 表引擎创建表:
接着,可以查询 catalog 中底层表的数据:
Iceberg 表引擎还支持模式演化功能,包括列的新增和移除、列名的修改,以及在原始数据类型之间的类型变更。
贡献者:Nikita Taranov 每次 ClickHouse 的新版本发布,都会对 JOIN 功能进行优化。这次的圣诞特别版本也不例外,带来了许多 JOIN 相关的增强功能!✨ 在 24.11 版本的发布文章中,我们提到并行哈希 JOIN 已成为 ClickHouse 的默认 JOIN 策略。在这里,我们将通过具体示例展示这一改进带来的性能提升。 我们在一台 AWS EC2 m6i.8xlarge 实例上进行了测试,该实例配置了 32 个 vCPU 和 128 GiB 内存。 测试数据集选用的是 TPC-H 数据集,扩展因子为 100,表示所有表中的总数据量约为 100 GB。 我们按照官方文档的指引,创建并加载了 8 个表,这些表模拟了一个批发供应商的数据仓库。 首先,我们在使用 ClickHouse 之前默认的 JOIN 策略(哈希 JOIN)时,运行了 TPC-H 基准查询集中第 3 个查询:
接下来,我们切换为 ClickHouse 新的默认 JOIN 策略(并行哈希 JOIN),运行相同的查询:
|








版权声明:本文为 clickhouse 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。